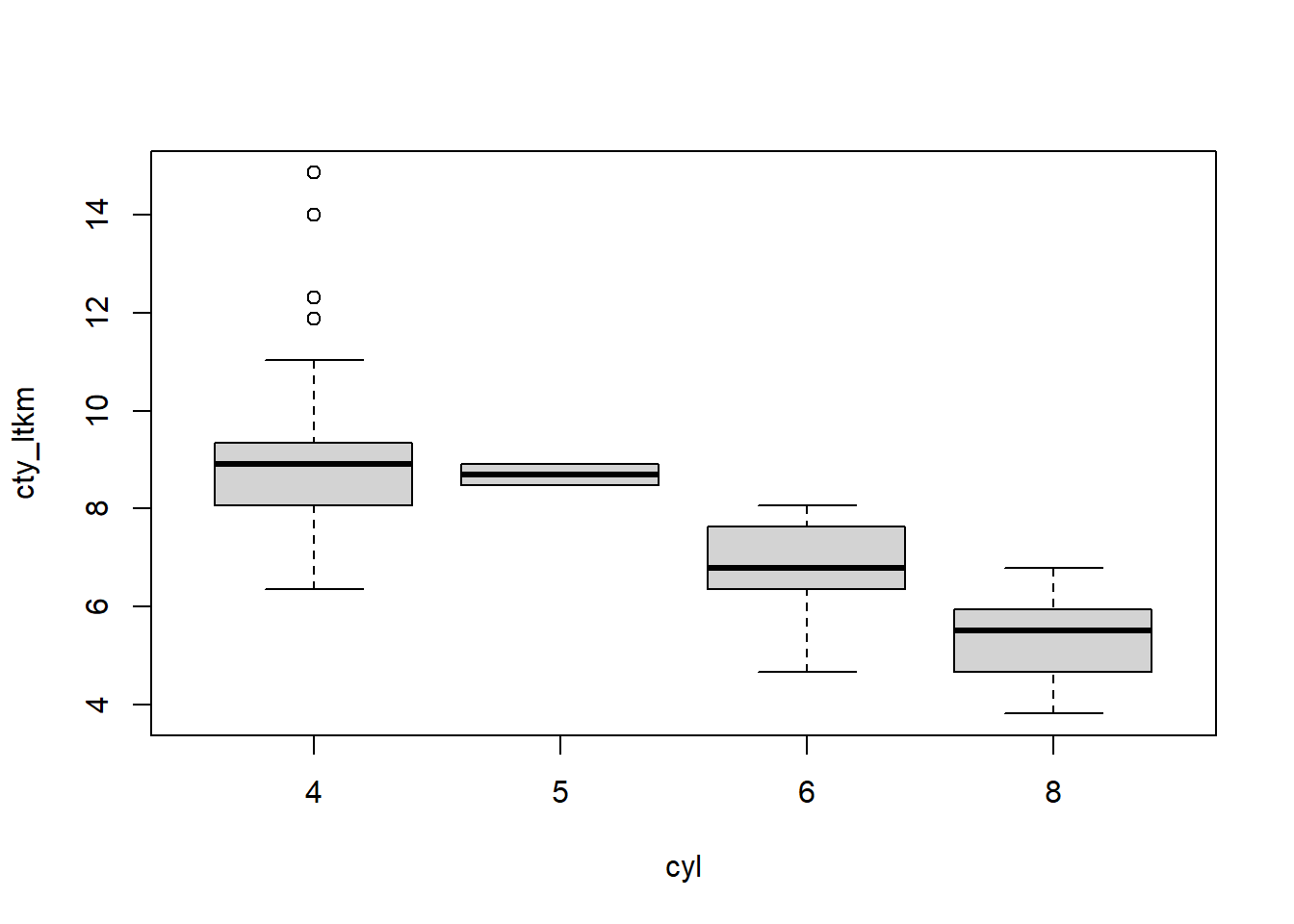Keşifçi Veri Analizi (Exploratory Data Analysis veya kısaca EDA), veri setinizi anlamak, içindeki örüntüleri ve ilişkileri belirlemek ve olası sorunları tanımlamak amacıyla veriye yakından bakmanızı sağlayan bir veri analizi yaklaşımıdır. EDA, verileri tanımanıza veya verilerdeki olası özellikler ve ilişkiler hakkında daha derin bir anlayış kazanmanıza yardımcı olabilir. EDA, yeni bir şey değildir, ancak EDA, birkaç nedenden dolayı yakın geçmişte önemli ölçüde büyümüştür:
Veriler her zamankinden daha hızlı ve daha büyük miktarlarda üretiliyor, bu yüzden incelememiz gereken çok şey var.
Bilgisayarlar ve yazılımlar (R gibi) EDA yapma fırsatlarını genişletmiştir.
İstatistiksel model seçeneklerindeki artış, genellikle doğrudan geleneksel bir modele gitmek yerine verilerimize daha yakından bakmamızı gerektirmektedir.
EDA, verilerinizin nihai analizi açısından genellikle istatistiksel değildir, ancak EDA’nın geçiş süreci olarak düşünülmesi gerekir. EDA’dan öğrendikleriniz modellemenize rehberlik edecek ve istatistiksel araçlar hakkında verdiğiniz kararları doğrudan bilgilendirecektir. R gibi programlama dilleri ve istatistiksel araçlar, EDA sürecini kolaylaştırmak ve verileri görselleştirmek için kullanışlıdır. EDA, veri madenciliği ve veri bilimi projelerinin başlangıcında sıklıkla kullanılır ve aşağıdaki adımları içerir:
Veri İçe Aktarma: İlk adım, analiz yapmak için veriyi içe aktarmaktır. Veriyi R ortamına çeşitli formatlardan (CSV, Excel, SQL veritabanları, vb.) içe aktarabilirsiniz.
Veriye Genel Bakış: Veri setinize ilk bakışta, kaç gözlem ve değişken olduğunu, değişken türlerini (sayısal, kategorik, metinsel vb.) ve eksik verilerin varlığını incelemelisiniz. Bu bilgi, veri hakkında ilk fikirlerinizi oluşturmanıza yardımcı olur.
Veri Görselleştirme: Verileri görselleştirmek, EDA’nın önemli bir parçasıdır. R’nin ggplot2 gibi kütüphaneleri, verilerinizi grafiklerle görselleştirmek için kullanışlı araçlar sunar. Histogramlar, kutu grafikleri, çubuk grafikleri ve dağılım grafikleri gibi grafikler oluşturarak verilerinizi daha iyi anlayabilirsiniz.
Merkezi Eğilim ve Dağılım Ölçüleri: Veri setinizin merkezi eğilimini (ortalama, medyan, mod) ve dağılımını (standart sapma, varyans, çeyrekler arası aralık) hesaplayarak verilerinizin genel özelliklerini değerlendirebilirsiniz.
Değişkenler Arası İlişkiler: Değişkenler arasındaki ilişkileri anlamak için korelasyon analizi, scatter plotlar ve faktör analizi gibi teknikleri kullanabilirsiniz.
Aykırı Değerler ve Eksik Veriler: Aykırı değerleri tanımlayın ve bunların analiz üzerindeki etkilerini değerlendirin. Ayrıca eksik verileri ele alın (örneğin, eksik verileri doldurma veya eksik gözlemleri çıkarma).
Veri Gruplama ve Alt Kümelere Bölme: İhtiyaca göre veriyi gruplara ayırabilir veya alt kümeler oluşturabilirsiniz. Bu, farklı veri alt kümeleri arasındaki farkları incelemek için kullanışlı olabilir.
Hipotez Testleri ve İstatistiksel Analiz: EDA süreci sırasında, veriler üzerinde belirli hipotezleri test etmek için istatistiksel testler (t-test, ANOVA, vb.) uygulayabilirsiniz. Bu, verilerinizde anlamlı farklılıkları veya özellikleri tespit etmenize yardımcı olur.
Sonuçların Yorumlanması: EDA sürecinin sonunda, elde edilen sonuçları yorumlamalı ve bulgularınızı raporlamalısınız. Bulgularınız, daha sonraki analiz aşamaları veya veri madenciliği projeleri için temel oluşturur.
EDA, veri analizi sürecinin önemli bir parçasıdır çünkü veriyi daha iyi anlamanızı ve daha ileri analizler için yol haritasını belirlemenizi sağlar. Aynı zamanda veri setinizdeki hataları veya tutarsızlıkları tespit etmenize ve düzeltmenize de yardımcı olur.
Veri ile Tanışma
Veri analizinin başlangıç aşamasında, verinin yapısına, ne tür değişkenler içerdiğine, çeşitli özet istatistiklerine bakmak ve gerekli ise ne tür dönüşümler yapmak gerektiğini bilmek önemlidir. Bu süreçler daha derin analizlere daha kolay devam edebilmek için de önemlidir. Bunları gerçekleştirmek için hem özet tablolar hem de grafikler yardımıyla verileri tanımak gerekmektedir.
Tek ve iki değişkenli olarak sayısal ve kategorik veri analizi mpg verisi kullanılarak yapılacaktır. Bu veri setinde 38 farklı aracın yakıt verileri bulunmaktadır.
# mpg verisi ggplot2 paketinde olduğundan paketi çağırıyoruzlibrary(ggplot2)head(mpg)
# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
manufacturer model displ year
Length:234 Length:234 Min. :1.600 Min. :1999
Class :character Class :character 1st Qu.:2.400 1st Qu.:1999
Mode :character Mode :character Median :3.300 Median :2004
Mean :3.472 Mean :2004
3rd Qu.:4.600 3rd Qu.:2008
Max. :7.000 Max. :2008
cyl trans drv cty
Min. :4.000 Length:234 Length:234 Min. : 9.00
1st Qu.:4.000 Class :character Class :character 1st Qu.:14.00
Median :6.000 Mode :character Mode :character Median :17.00
Mean :5.889 Mean :16.86
3rd Qu.:8.000 3rd Qu.:19.00
Max. :8.000 Max. :35.00
hwy fl class
Min. :12.00 Length:234 Length:234
1st Qu.:18.00 Class :character Class :character
Median :24.00 Mode :character Mode :character
Mean :23.44
3rd Qu.:27.00
Max. :44.00
df <- mpg# class değişkenini faktöre çevirip, kategorilerine bakalımdf$class <-factor(df$class)levels(df$class)
Veri analizi, birçok farklı değişken türünün incelenmesini gerektirir. Bu değişkenler arasında sürekli değişkenler özellikle önemlidir. Sürekli değişkenler, belirli bir aralıktaki değerleri alabilen ve sonsuz sayıda mümkün değer içeren değişkenlerdir. Örnek olarak, yaş, gelir, sıcaklık gibi değerler sürekli değişkenlere örnektir. Sürekli değişkenlerin analizi, verileri anlamak ve içindeki örüntüleri keşfetmek için kullanılır. Bu analiz, genellikle aşağıdaki adımları içerir:
Veri Görselleştirme:Sürekli değişkenlerin analizine başlamak için verilerinizi görselleştirmek önemlidir. Histogramlar, kutu grafikleri, yoğunluk grafikleri ve saçılım grafikleri gibi grafikler, veri dağılımını ve örüntülerini görsel olarak incelemenize yardımcı olur. Bu grafikler, veri setinizin merkezi eğilimini (ortalama veya medyan), yayılımını ve aykırı değerleri hızla görmeye yardımcı olur.
Merkezi Eğilim ve Dağılım Ölçüleri: Sürekli değişkenlerin merkezi eğilimini ve dağılımını hesaplamak verileri özetlemenin önemli bir yoludur. Bu ölçümler, veri setinin merkezi noktasını ve veri noktalarının nasıl dağıldığını anlamamıza yardımcı olur. Örnek olarak, ortalama (mean), medyan (median), standart sapma (standard deviation) ve varyans (variance) gibi ölçümler bu aşamada kullanılır.
Korelasyon Analizi: Eğer birden fazla sürekli değişken arasındaki ilişkiyi anlamak istiyorsanız, korelasyon analizi yapabilirsiniz. Korelasyon, iki değişken arasındaki ilişkinin gücünü ve yönünü ölçer. Korelasyon katsayısı, bu ilişkiyi değerlendirmek için kullanılır. Pozitif bir korelasyon, iki değişkenin aynı yönde değiştiğini, negatif bir korelasyon ise iki değişkenin ters yönde değiştiğini gösterir.
Hipotez Testleri: Sürekli değişkenler arasındaki farklılıkları değerlendirmek için hipotez testleri kullanılabilir. Örneğin, iki grup arasındaki ortalama değerlerin istatistiksel olarak anlamlı bir farklılık gösterip göstermediğini belirlemek için t-testleri veya ANOVA analizi kullanılabilir.
Güven Aralıkları: Sürekli değişkenlerin analizi sırasında, belirli bir parametre (örneğin, ortalama) hakkında güven aralıkları hesaplanabilir. Bu güven aralıkları, parametrenin belirli bir güven düzeyinde bulunduğu aralığı gösterir. Bu, parametrenin tahmini kesinliğini değerlendirmek için kullanışlıdır.
Sürekli değişkenlerin analizi, verileri anlama ve kararlarınızı destekleme sürecinin önemli bir parçasıdır. İyi bir analiz, veri setinizdeki örüntüleri ve ilişkileri açığa çıkarmanıza yardımcı olur ve bilinçli kararlar almanıza yardımcı olur. Bu nedenle, sürekli değişkenlerin analizi yaparken yukarıda belirtilen adımları takip etmek önemlidir.
# cty ve hwy değişkenlerini inceleyelim. # cty şehiriçi, hwy şehirarasını ifade ediyor.summary(df$cty)
Min. 1st Qu. Median Mean 3rd Qu. Max.
9.00 14.00 17.00 16.86 19.00 35.00
var(df$cty)
[1] 18.11307
mean(df$cty)
[1] 16.85897
summary(df$hwy)
Min. 1st Qu. Median Mean 3rd Qu. Max.
12.00 18.00 24.00 23.44 27.00 44.00
var(df$hwy)
[1] 35.45778
mean(df$hwy)
[1] 23.44017
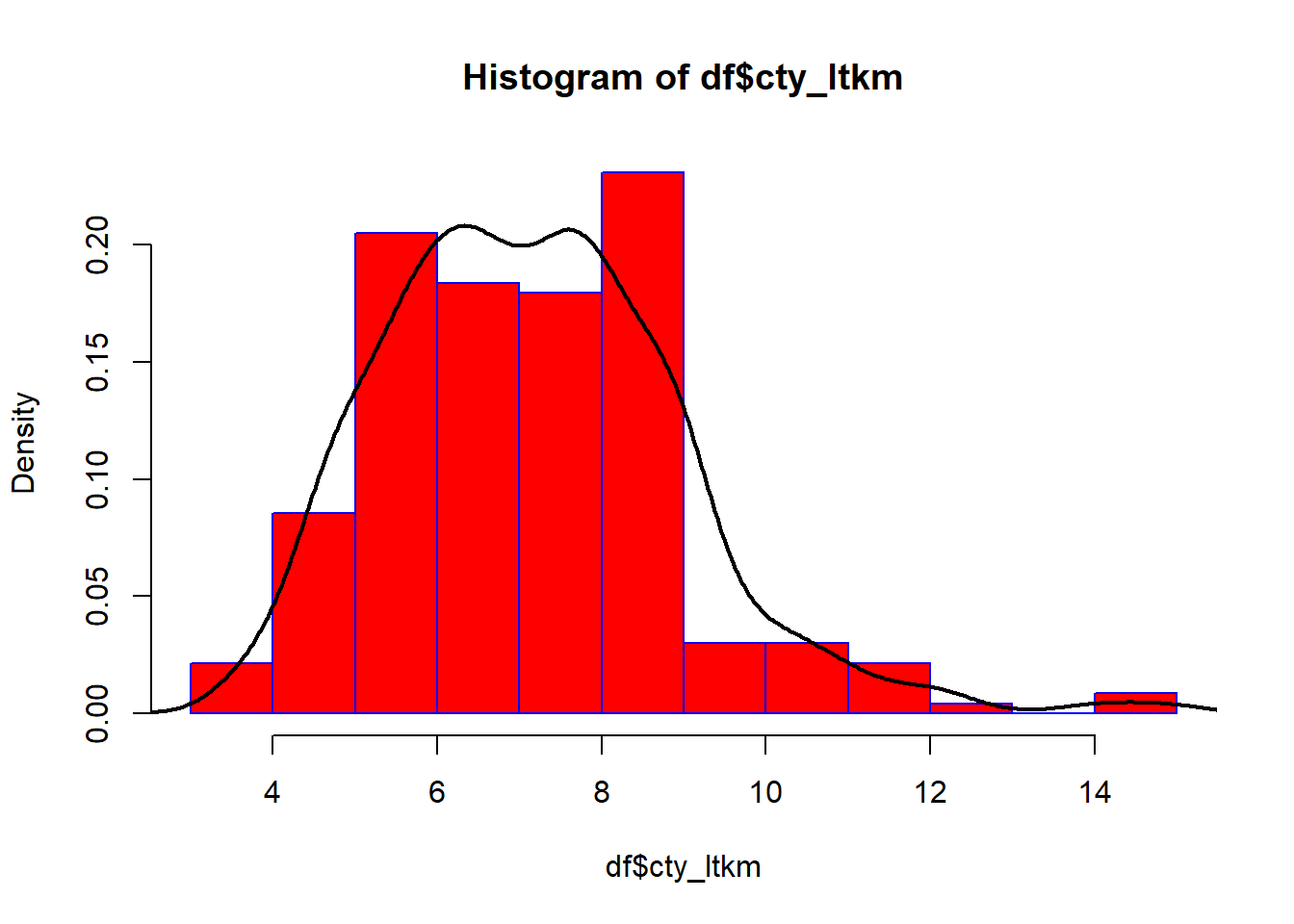
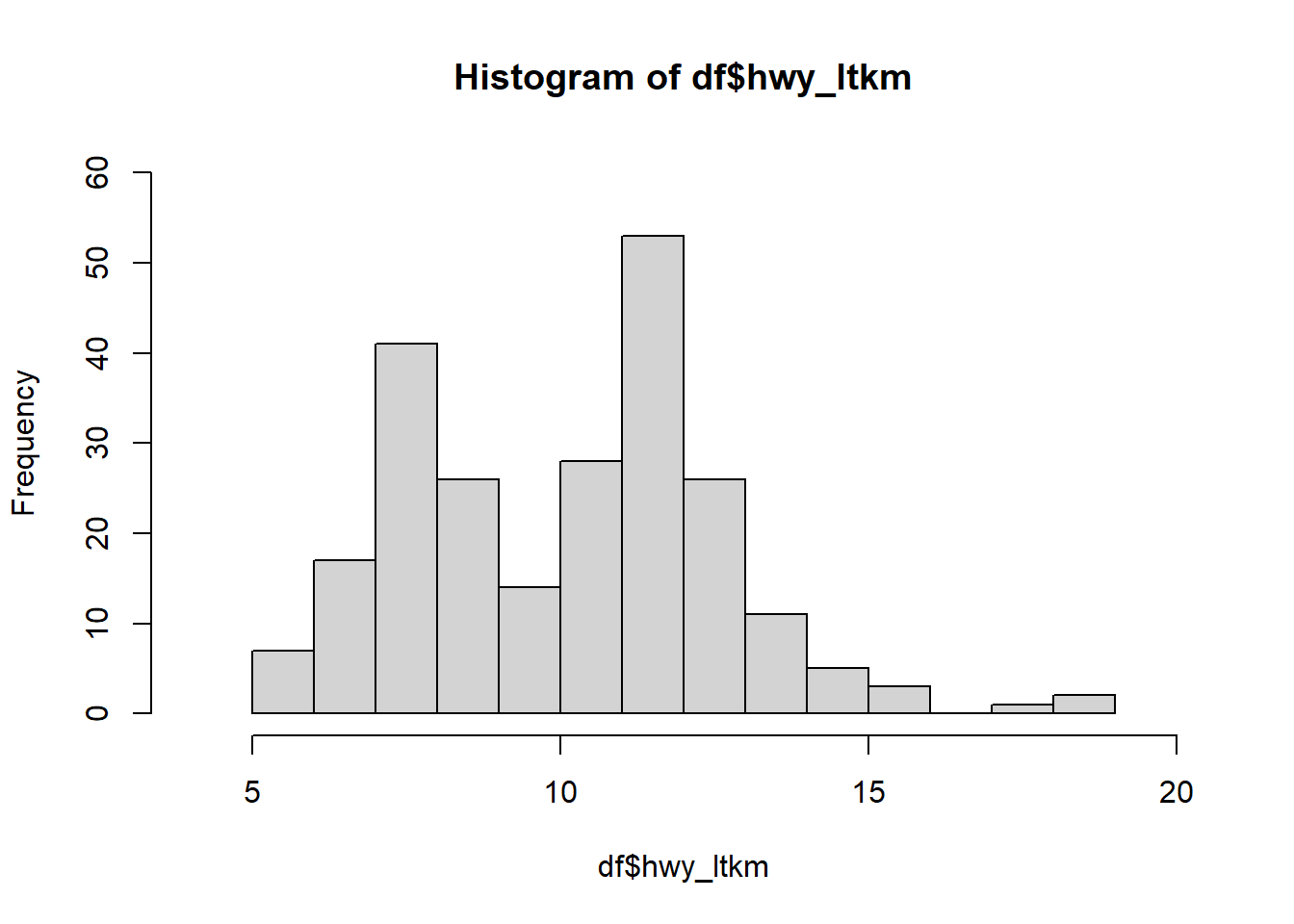
# 1 mile= 1.609 km# 1 galon = 3.79 lt# litre başına km hesaplamagalonmil_to_ltkm <-function(x){ km <- x *1.609/3.79return(km)}df$cty_ltkm <-galonmil_to_ltkm(df$cty)df$hwy_ltkm <-galonmil_to_ltkm(df$hwy)quantile(df$cty_ltkm)
# şehirlerarası araçların % 75'i 1 lt ile 11.46 km den az yol alıyor.# değişken dağılımı için histogram grafiği kullanılabilir.hist(df$cty_ltkm,freq =FALSE,col ="red",border ="blue")lines(density(df$cty_ltkm), col ="black", lwd =2,)
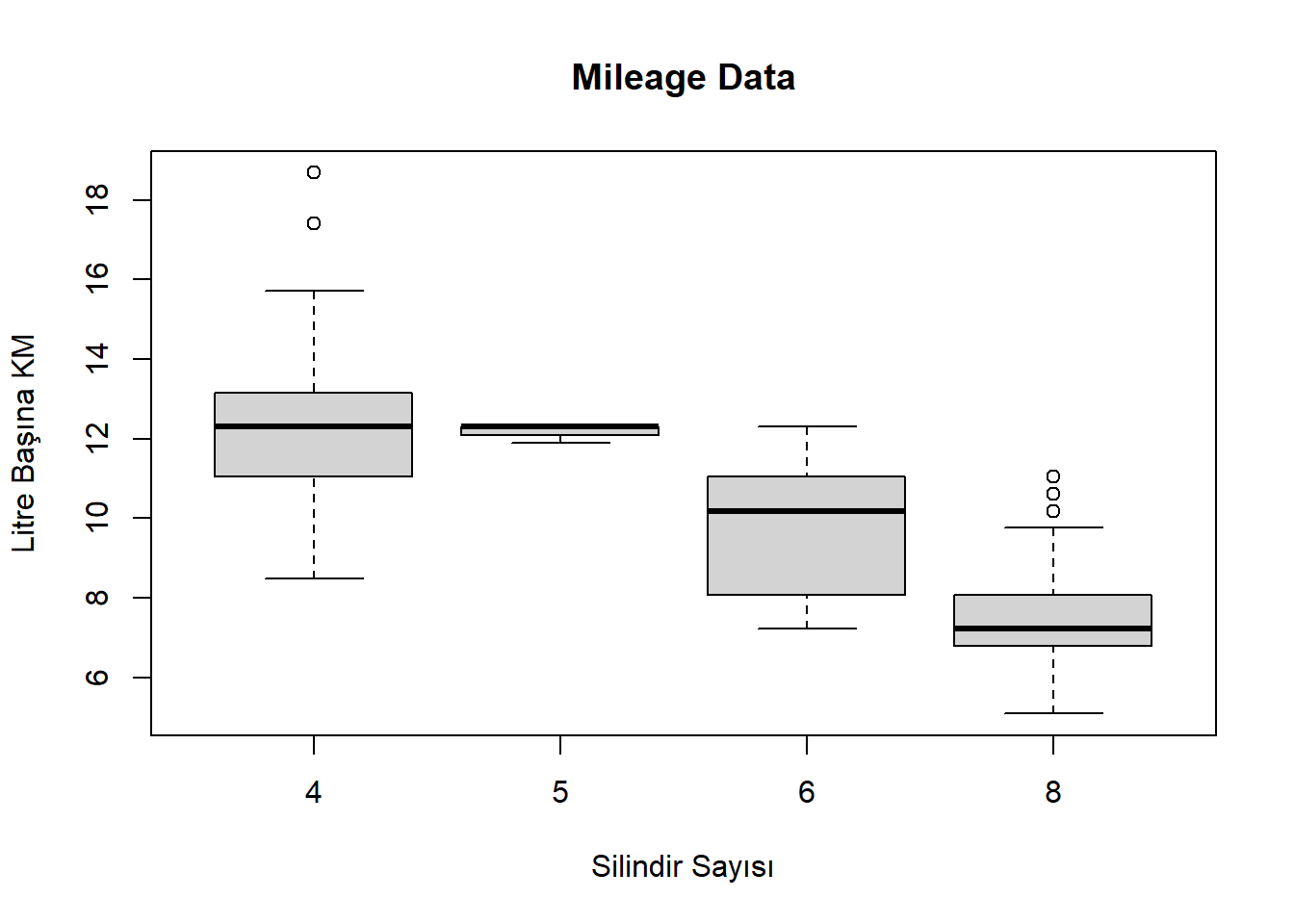
boxplot(hwy_ltkm ~ cyl, data = df, xlab ="Silindir Sayısı",ylab ="Litre Başına KM", main ="Mileage Data")
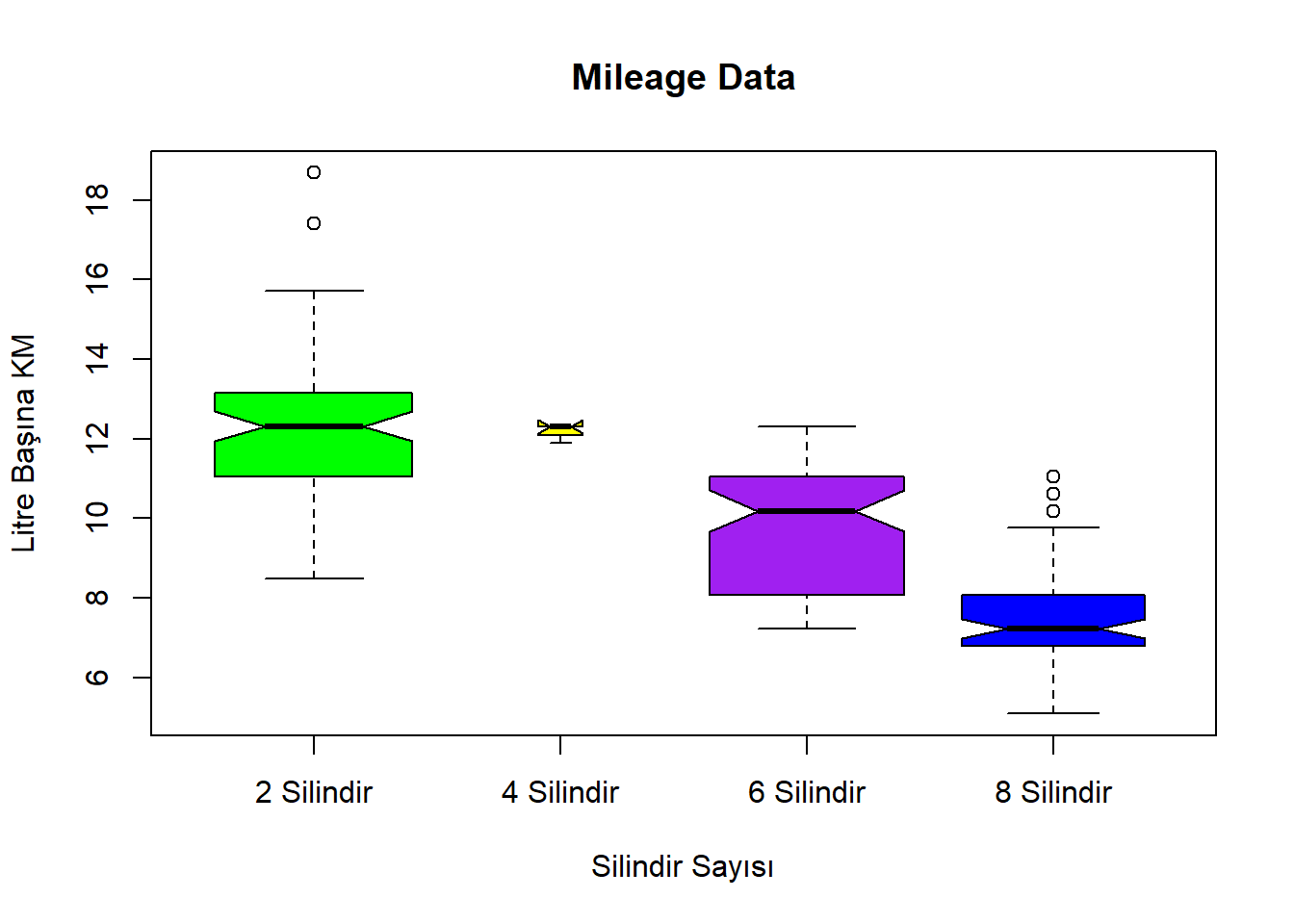
boxplot(hwy_ltkm ~ cyl, data = df, xlab ="Silindir Sayısı",ylab ="Litre Başına KM", main ="Mileage Data",notch =TRUE, varwidth =TRUE, col =c("green","yellow","purple","blue"),names =c("2 Silindir","4 Silindir","6 Silindir","8 Silindir"))
Warning in (function (z, notch = FALSE, width = NULL, varwidth = FALSE, : some
notches went outside hinges ('box'): maybe set notch=FALSE
# Sürekli iki değişken incelemek istersek;# displ ve cty_ltkm değişkenlerini inceleyelim# displ motor hacmini ifade ediyorsummary(df$displ)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.600 2.400 3.300 3.472 4.600 7.000
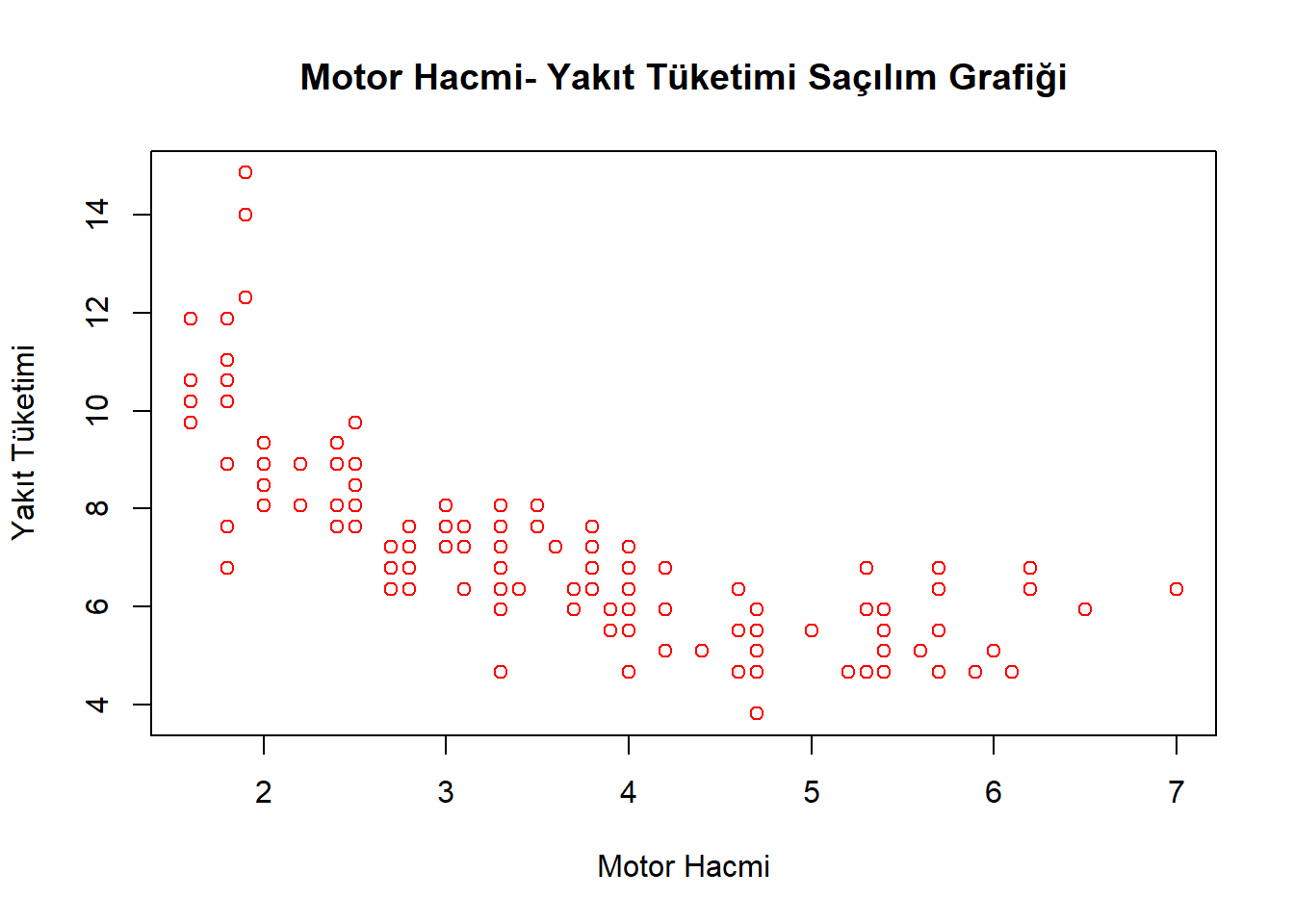
with(df,cor(displ,cty_ltkm))
[1] -0.798524
# motor hacmi ile lt başına km ters ilişkiliplot(df$displ,df$cty_ltkm, main ="Motor Hacmi- Yakıt Tüketimi Saçılım Grafiği",col="red",xlab ="Motor Hacmi",ylab ="Yakıt Tüketimi")
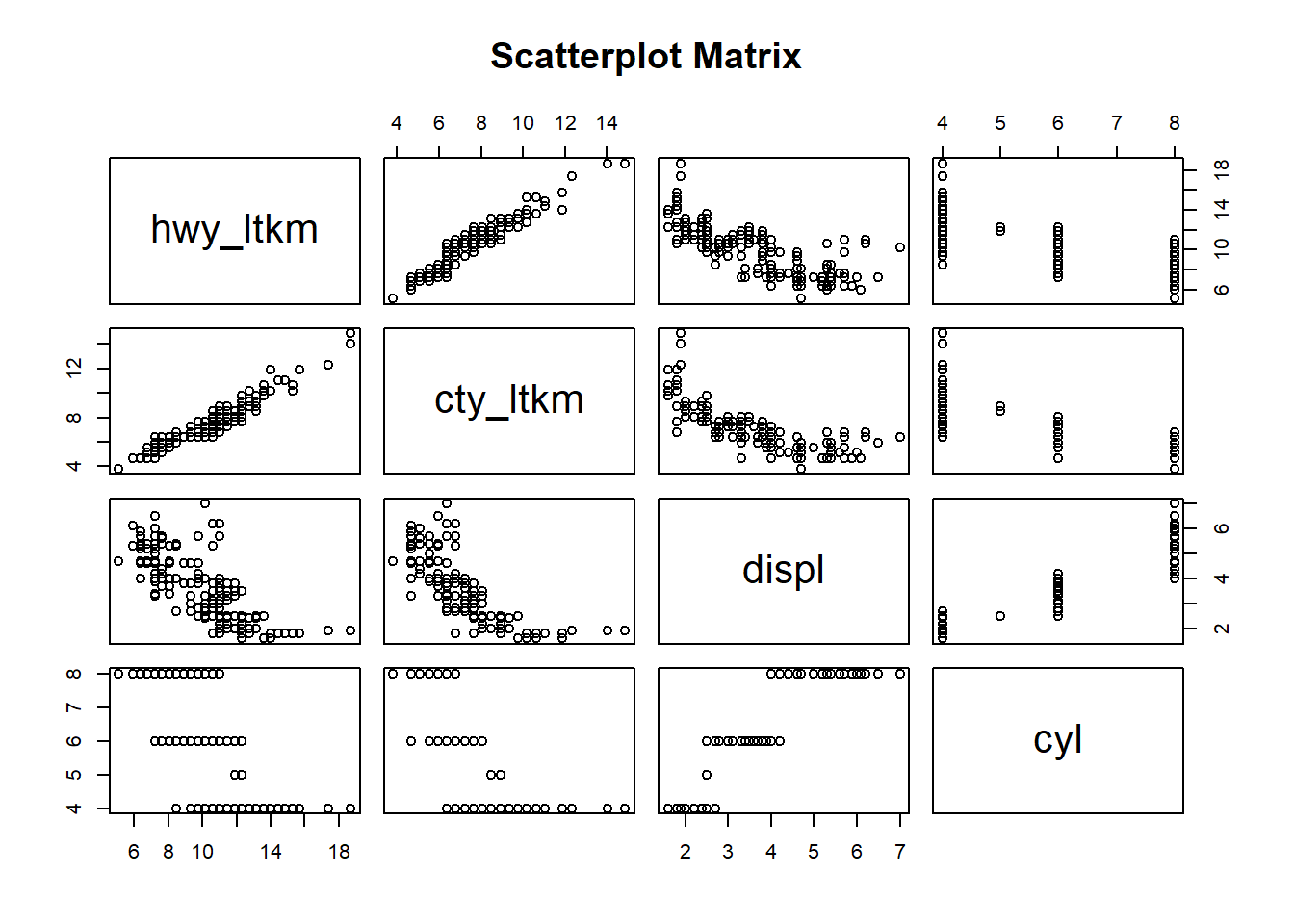
# birden fazla değişkenin saçılım grafiğipairs(~hwy_ltkm+cty_ltkm+displ+cyl,data = df,main ="Scatterplot Matrix")
Kategorik Değişkenler
Veri analizi sürecinde, kategorik değişkenler (veya gruplar) genellikle çok önemli bir rol oynar. Kategorik değişkenler, belirli bir sınıfı veya kategoriyi temsil eden değişkenlerdir ve tipik olarak metin veya sembollerle ifade edilirler. Örnek olarak, cinsiyet, eğitim seviyesi, ürün kategorileri gibi değişkenler kategorik değişkenlere örnektir. Kategorik değişkenlerin analizi, bu değişkenlerin içindeki örüntüleri, dağılımları ve ilişkileri anlamamıza yardımcı olur. Aşağıda, kategorik değişkenlerin analizi için izlenebilecek temel adımları bulabilirsiniz:
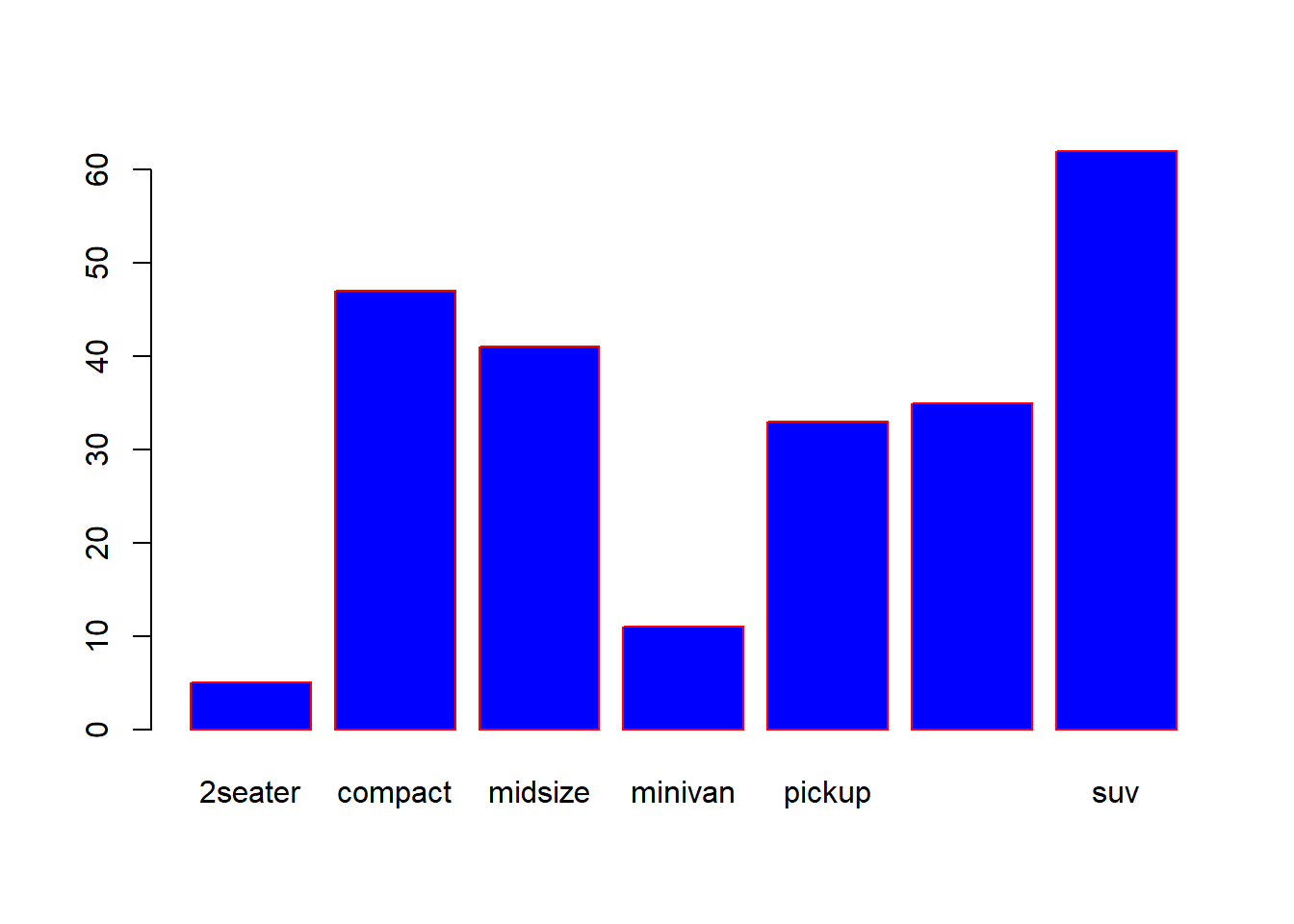
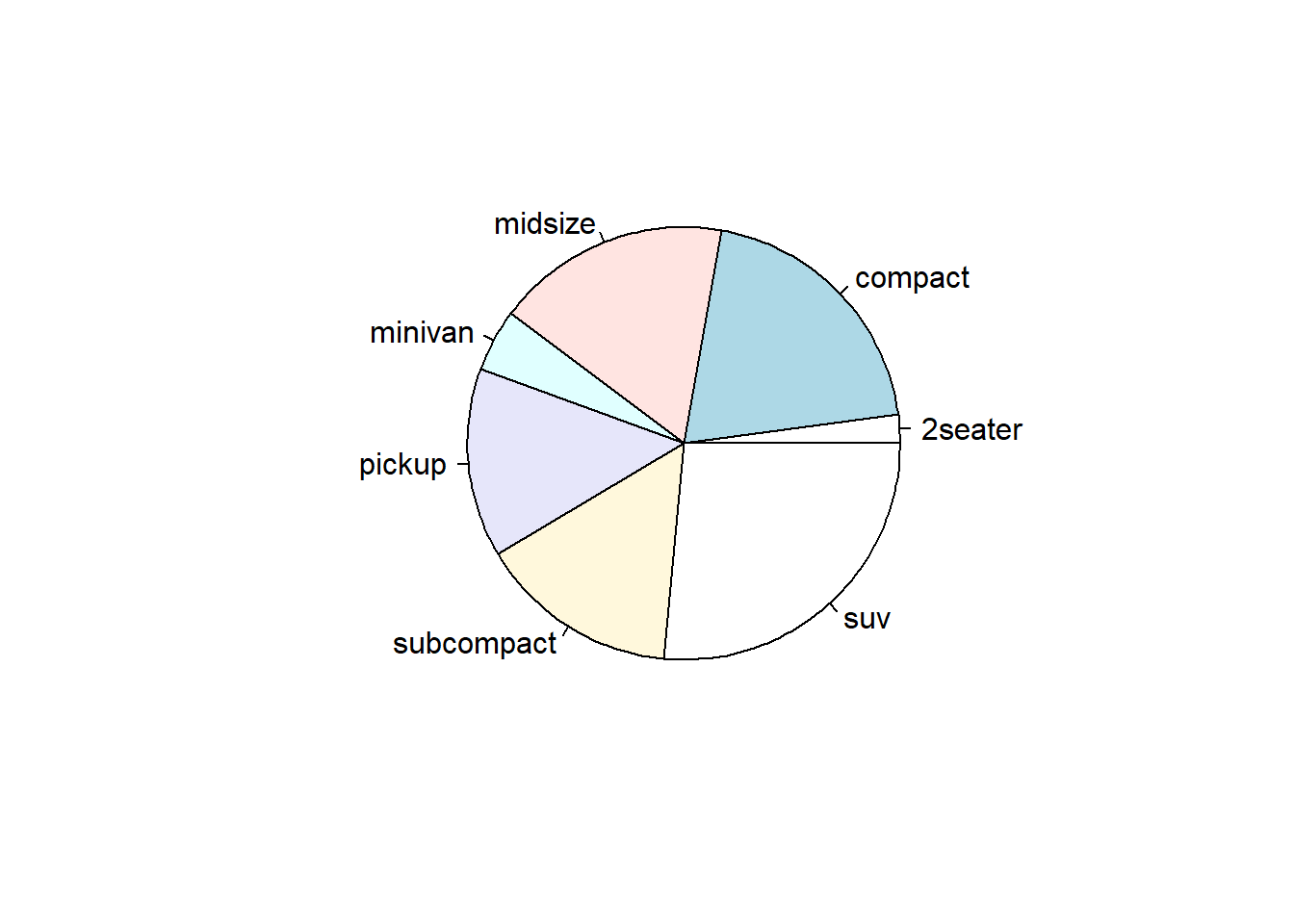
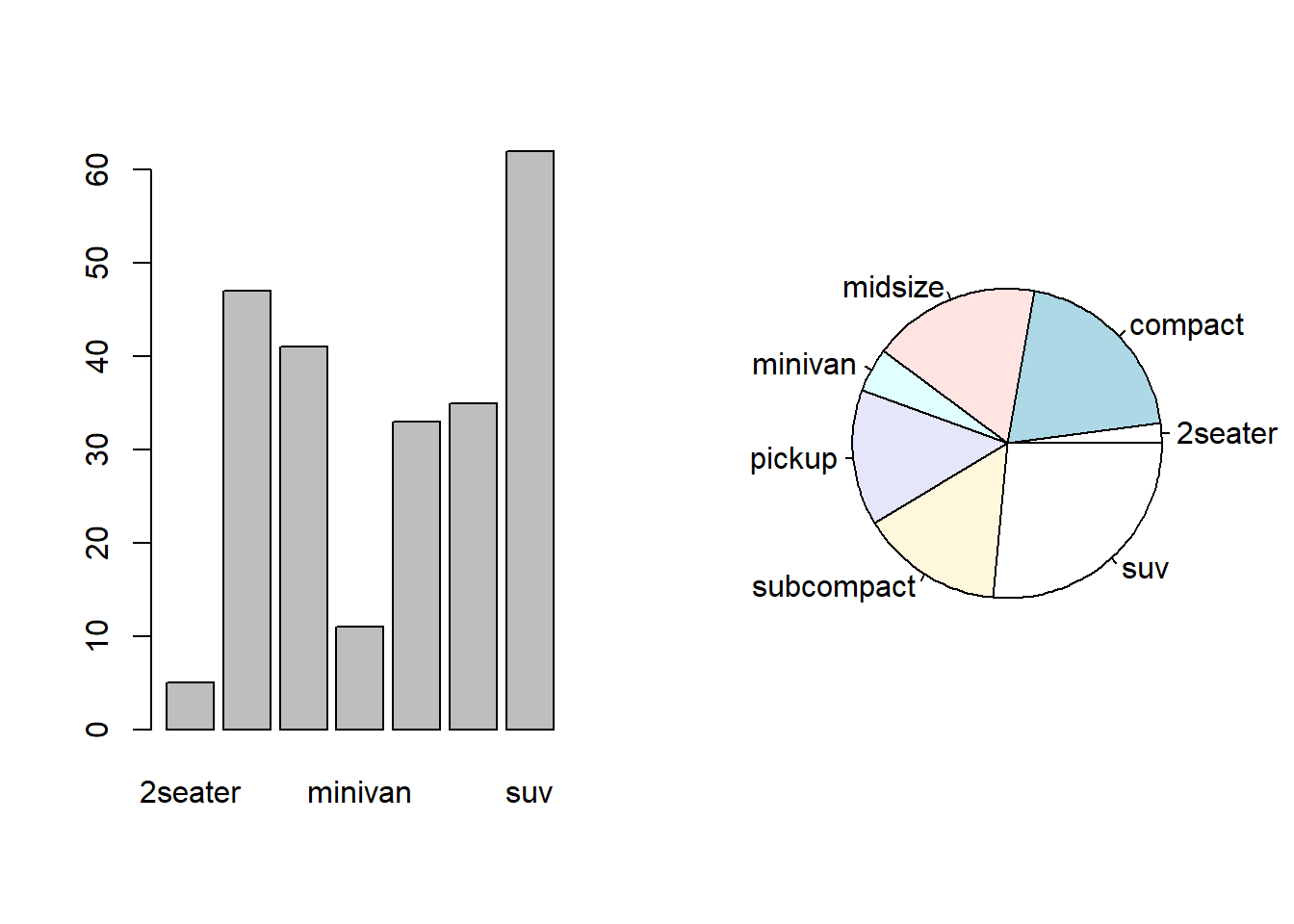
Frekans Tabloları ve Görselleştirme: Kategorik değişkenlerin frekans tablolarını ve grafiklerini oluşturarak, her kategori veya sınıfın veri setinde ne kadar sık görüldüğünü anlayabilirsiniz. Örneğin, bar grafikleri, pasta grafikleri veya çubuk grafikleri kullanarak kategori frekanslarını görselleştirebilirsiniz. summary() ve table() gibi R fonksiyonları ile bu verileri inceleyebilirsiniz.
İlişkileri İnceleme: Kategorik değişkenler arasındaki ilişkileri anlamak önemlidir. İki kategorik değişken arasındaki ilişkiyi değerlendirmek için çapraz tablolar (cross-tabulation) ve ki-kare (chi-squared) istatistiksel testleri kullanabilirsiniz. Bu testler, iki değişken arasındaki bağımlılığı değerlendirmek için kullanılır.
İstatistiksel Testler: Kategorik değişkenlerin analizi sırasında, gruplar arasındaki farkları değerlendirmek için hipotez testleri kullanabilirsiniz. İki kategorik değişken arasındaki ilişkinin istatistiksel olarak anlamlı olup olmadığını belirlemek için ki-kare testi veya Fisher’in kesin testi gibi testler kullanabilirsiniz. Ayrıca ANOVA gibi testler, bir kategorik değişkenin birden fazla grup üzerindeki etkisini değerlendirmek için kullanılabilir.
Veri Görselleştirme: Kategorik değişkenlerin analizinde, gruplar arasındaki farkları daha iyi anlamak için grafikler kullanabilirsiniz. Bar grafikleri, grupların frekanslarını görselleştirmek için sıklıkla kullanılırken, gruplar arasındaki ilişkiyi anlamak için mozaik grafikleri veya heatmap’leri de kullanabilirsiniz.
Kategorik değişkenlerin analizi, veri setinizin içindeki desenleri ve ilişkileri anlamanıza yardımcı olur. Bu analiz, kararlarınızı desteklemek ve veriyi daha iyi anlamak için önemlidir. R programlama dili, kategorik değişkenlerin analizi için bir dizi kullanışlı fonksiyon ve paket sunar. Bu adımları takip ederek, veri analiz projelerinizde kategorik değişkenleri etkili bir şekilde analiz edebilirsiniz.
# class ve trans değişkenlerine bakalım# class araç sınıfı, trans ise vites türünü ifade ediyor.summary(df$class)
proportions(xtabs(~ manufacturer + year, data = df), 1)
year
manufacturer 1999 2008
audi 0.5000000 0.5000000
chevrolet 0.3684211 0.6315789
dodge 0.4324324 0.5675676
ford 0.6000000 0.4000000
honda 0.5555556 0.4444444
hyundai 0.4285714 0.5714286
jeep 0.2500000 0.7500000
land rover 0.5000000 0.5000000
lincoln 0.6666667 0.3333333
mercury 0.5000000 0.5000000
nissan 0.4615385 0.5384615
pontiac 0.6000000 0.4000000
subaru 0.4285714 0.5714286
toyota 0.5882353 0.4117647
volkswagen 0.5925926 0.4074074
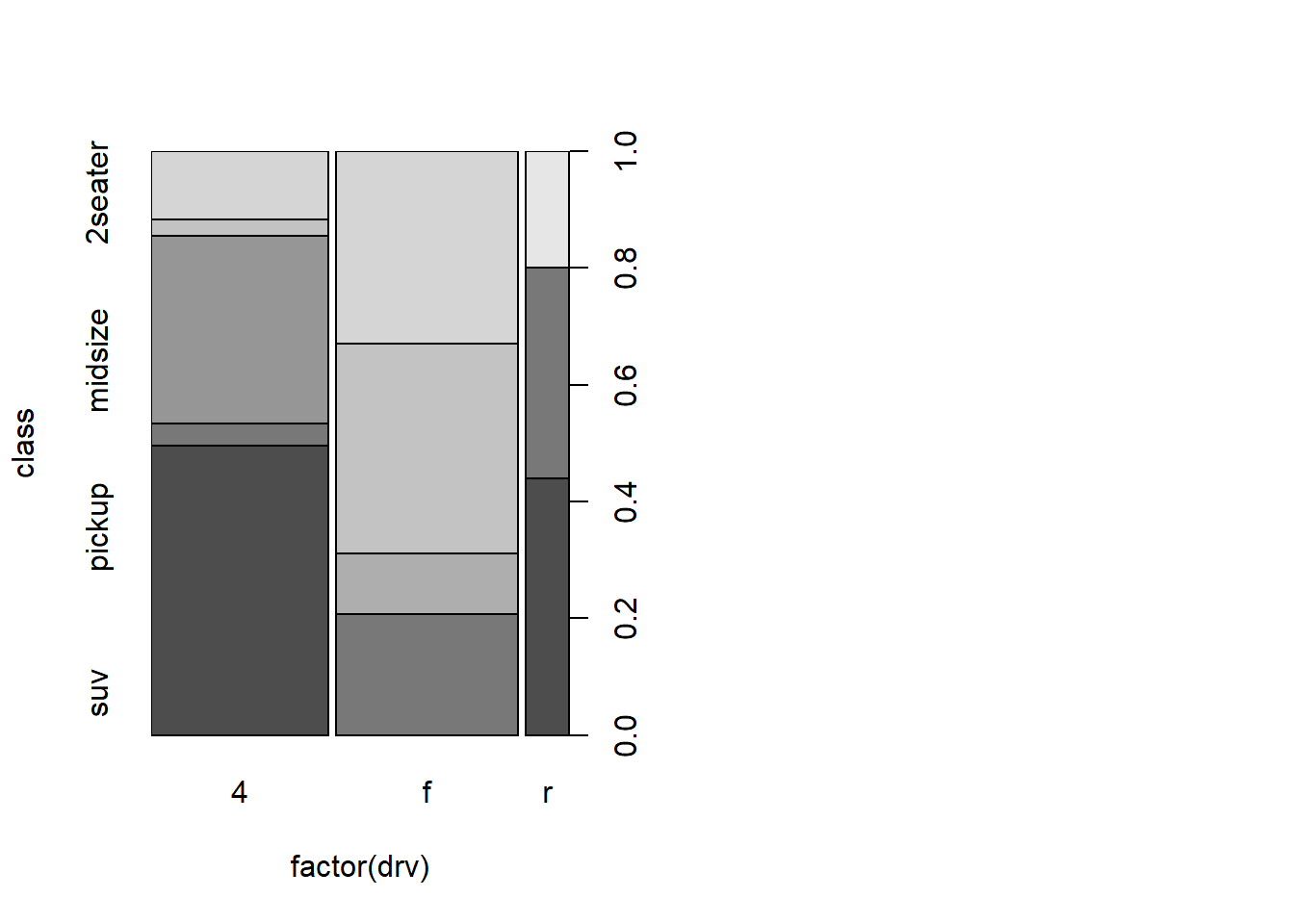
# araç sınıfı ile drv değişkenine birlikte bakalım# f = front-wheel drive (önden çekiş), # r = rear wheel drive (arkadan çekiş), # 4 = 4wd (4 çeker)plot(class ~factor(drv), data = df)
Eğer hem sürekli hem de kategorik değişkenleri incelemek istersek, benzer şekilde görselleştirme ve kategoriler arasında merkezi eğilim ölçüleri hesaplanabilir. Bunlar dışında uygun istatistiksel testler de gerçekleştirilebilir.
# Silindir düzeyinde yakıt tüketimi tapply(df$cty_ltkm, df$cyl, mean)
4 5 6 8
8.920545 8.703034 6.883968 5.337052
# Same using aggregate()aggregate(cty_ltkm ~ cyl, data = df, FUN = mean)
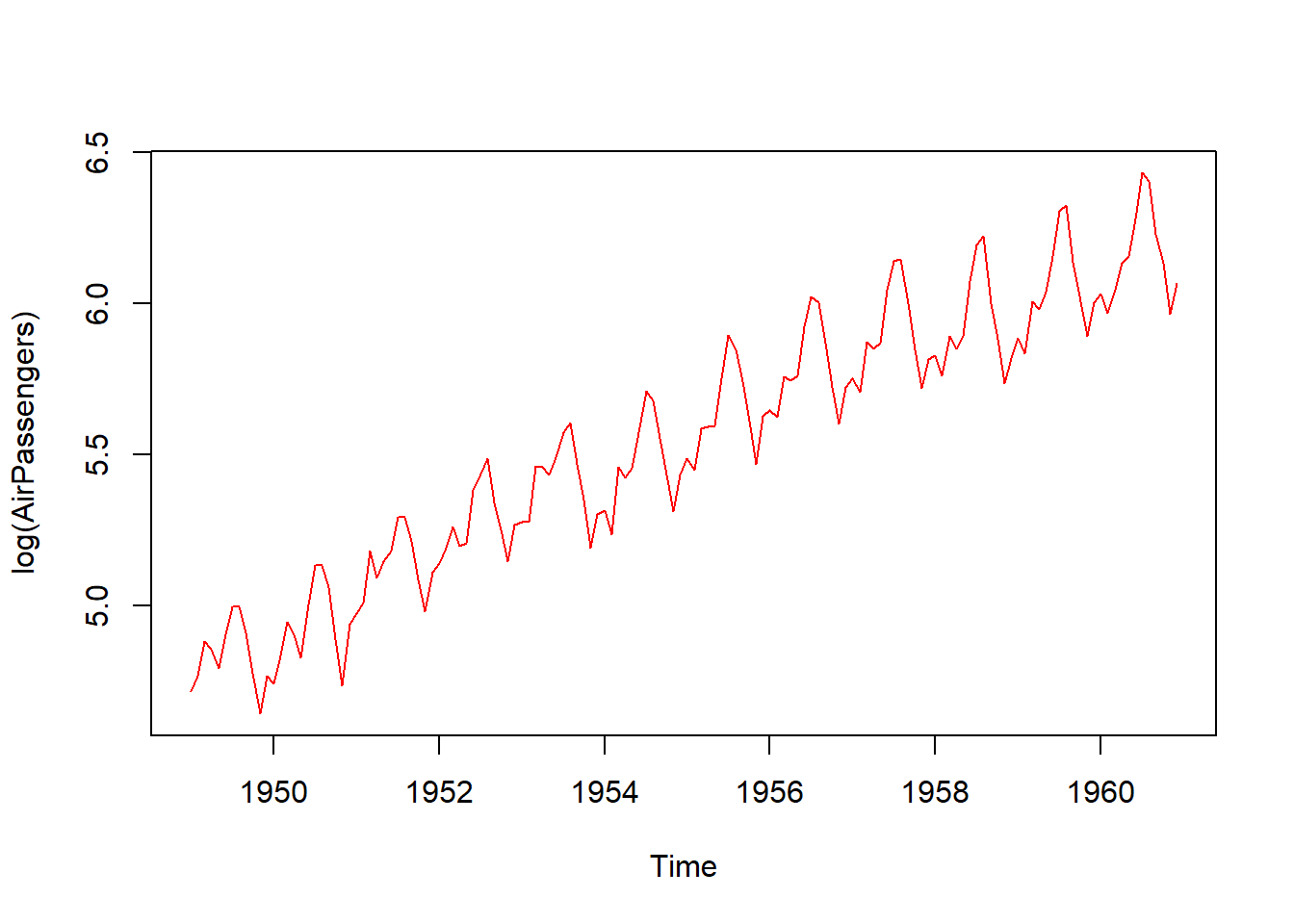
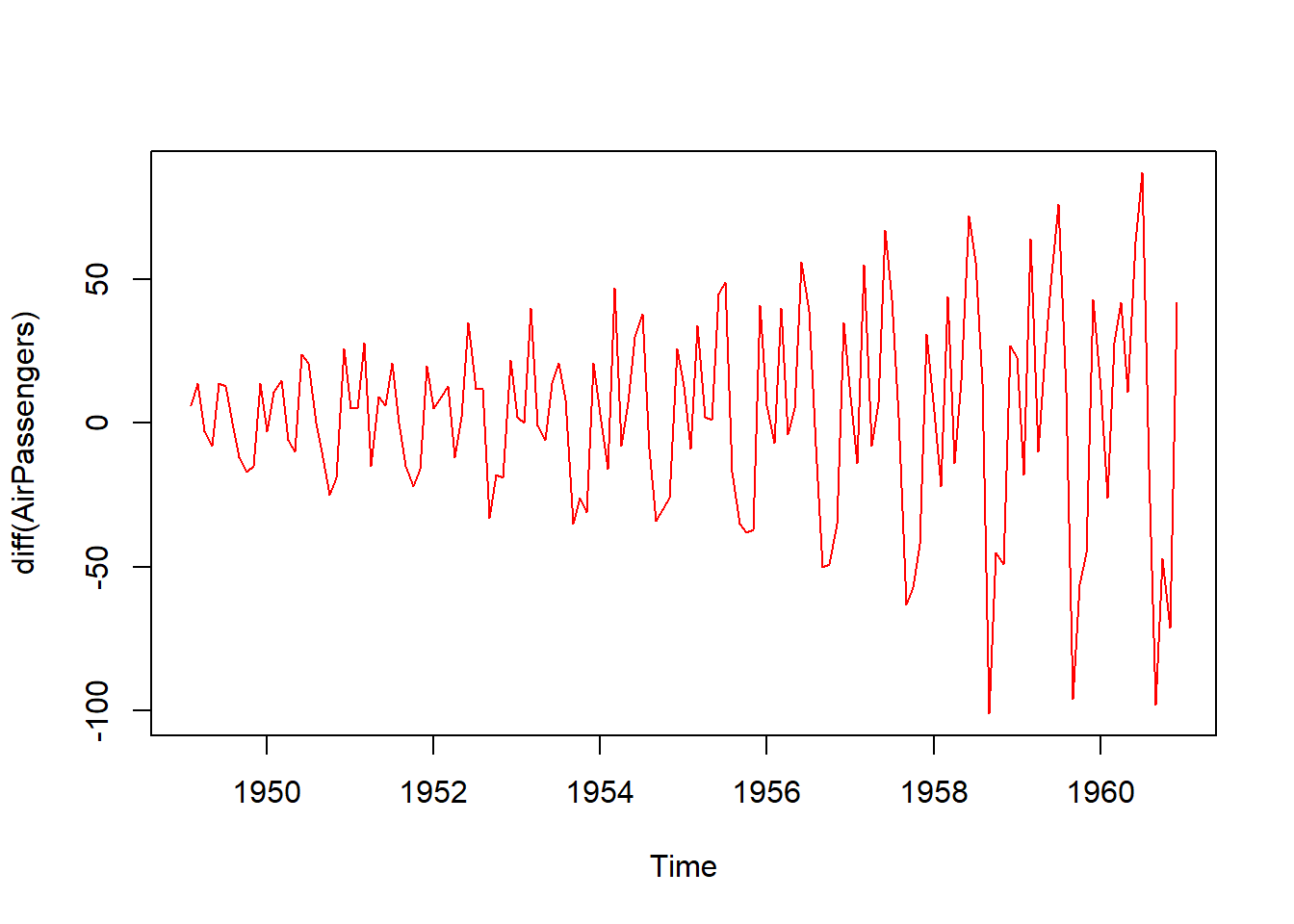
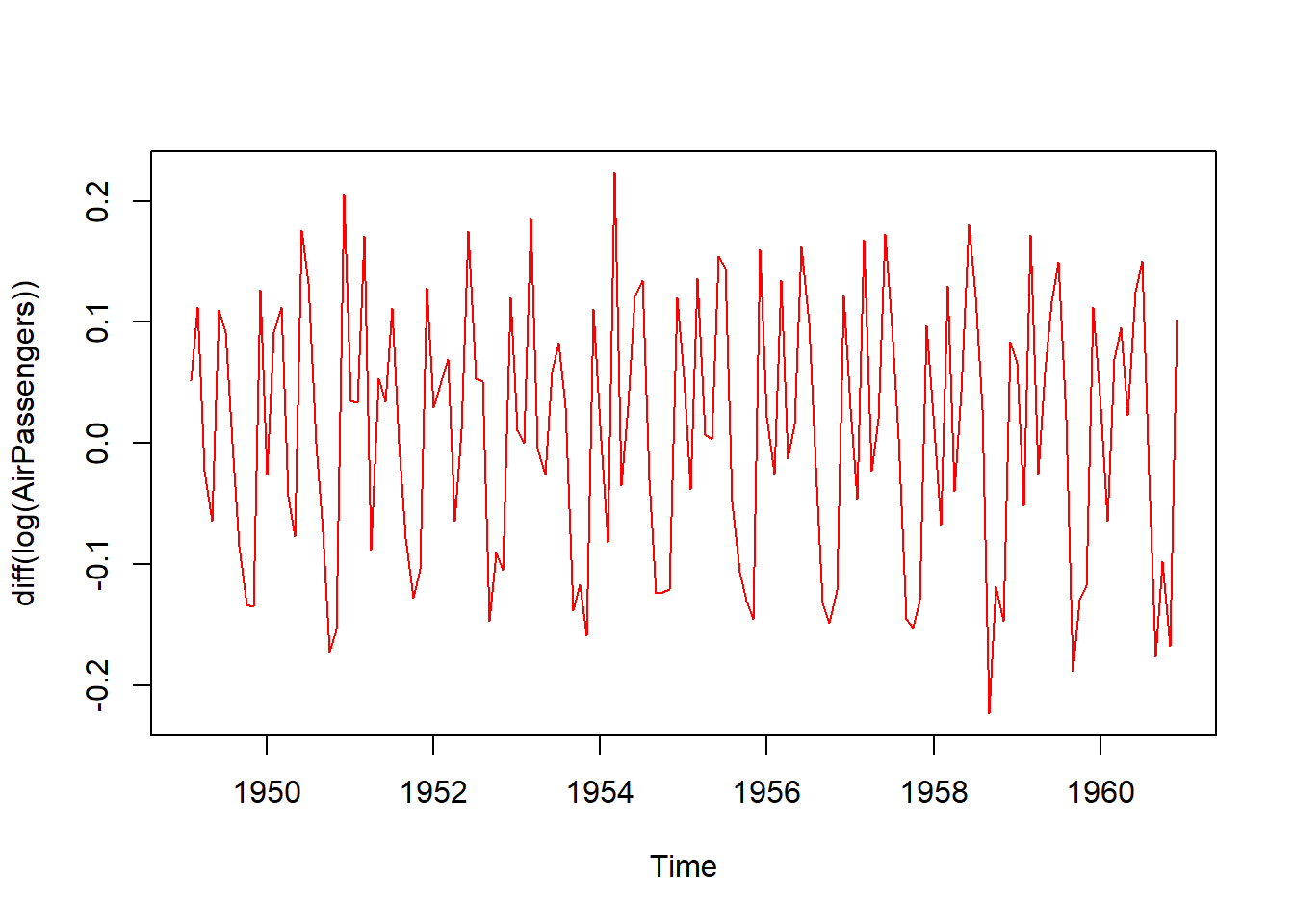
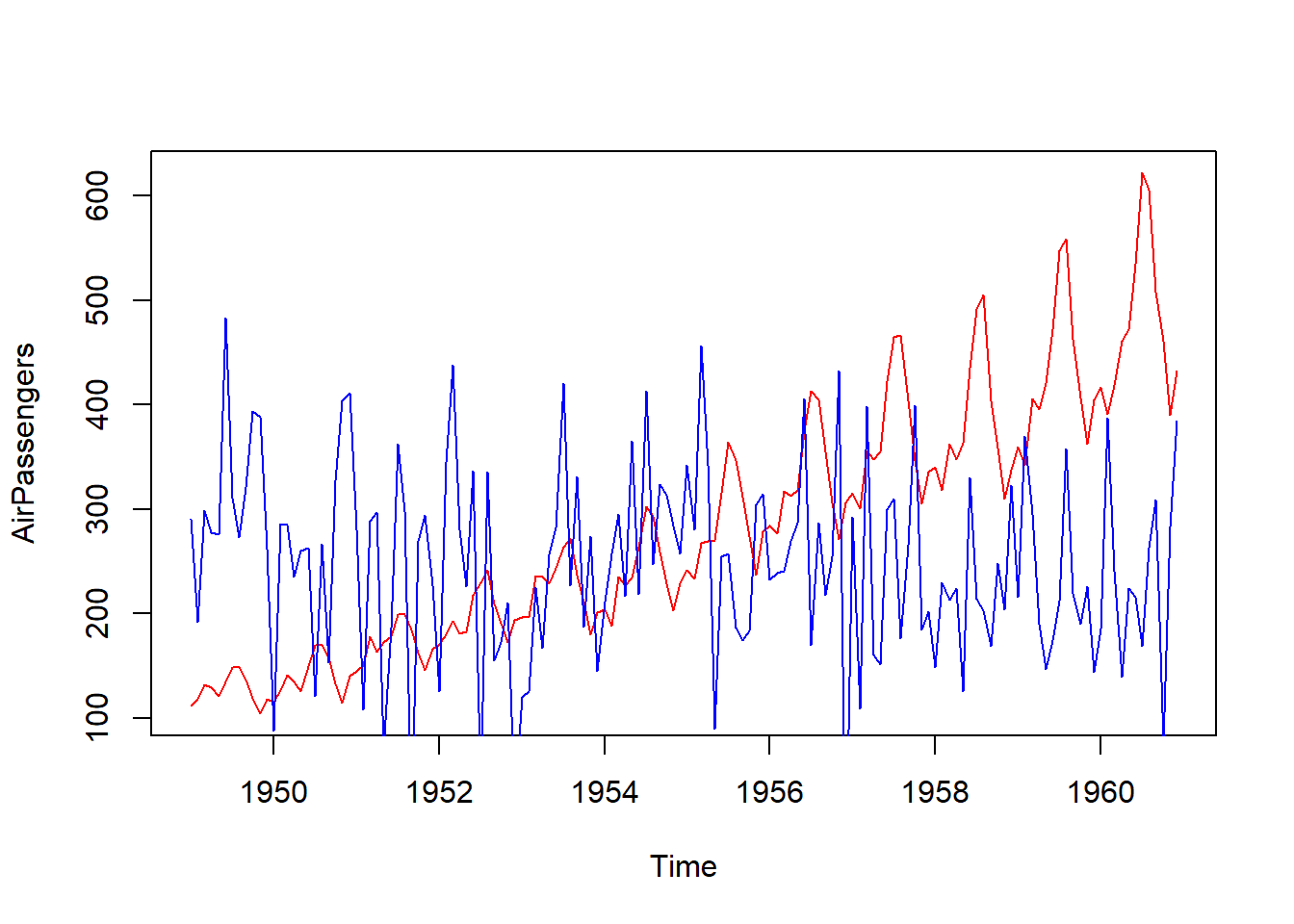
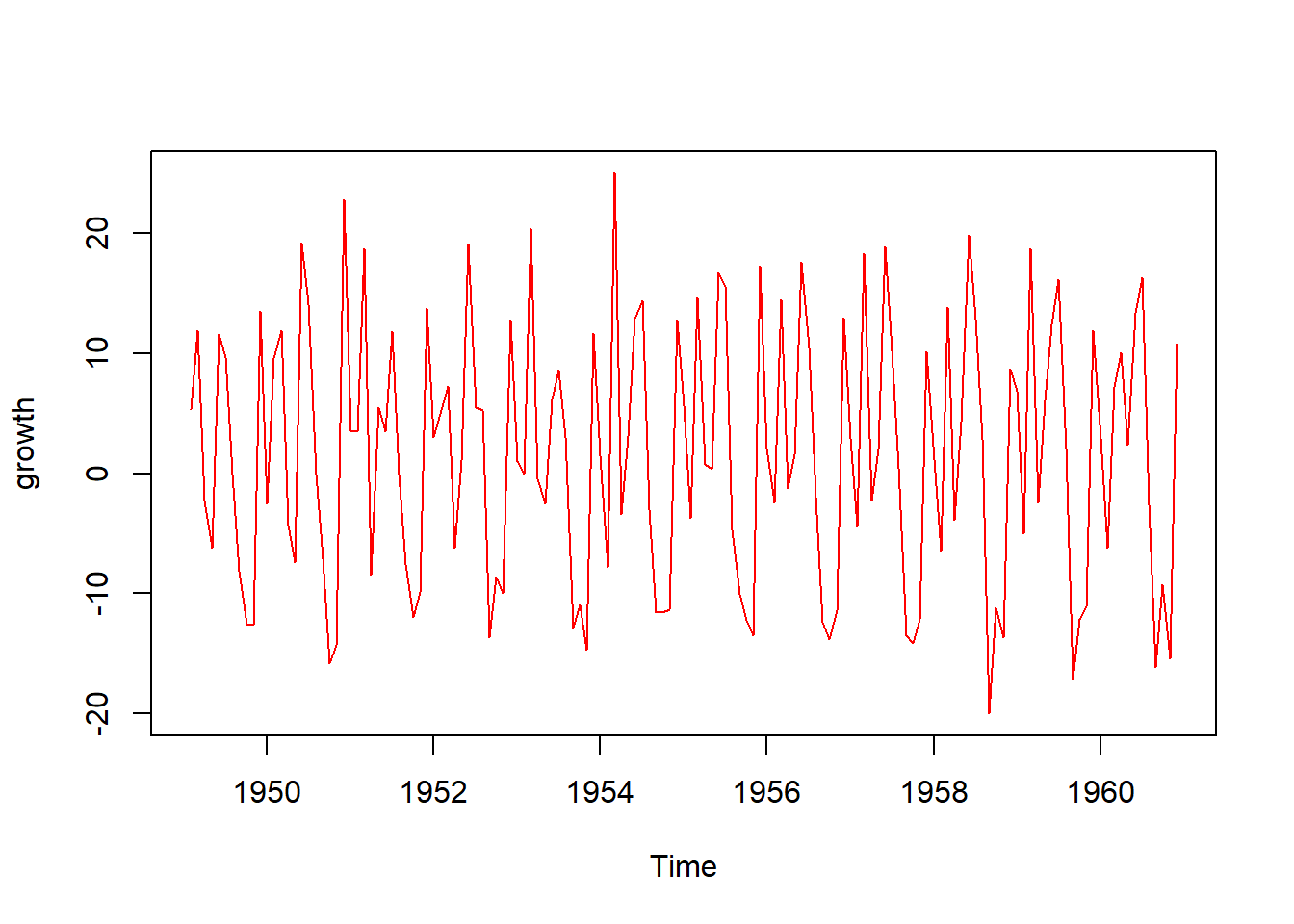
R programlama dili, zaman serileri analizi için kapsamlı bir dizi fonksiyon ve paket sunar. Zaman serileri analizi, zaman içindeki veri noktalarının örüntülerini ve trendlerini incelemeyi amaçlar. R’de zaman serileri ile çalışmak için ts (time series) nesnesi kullanılır. Bu nesne, zaman serisi verilerini zaman dilimleri (örneğin aylar, yıllar) veya tarihler ile ilişkilendirerek işlem yapmanıza olanak tanır.
Veri analizi için skimr paketi de kullanılabilir. skimr, R programlama dilinde veri setlerinin hızlı bir şekilde özetlenmesini sağlayan bir pakettir. Veri setlerinin yapısını, özelliklerini ve bazı istatistiksel özetlerini görsel ve açıklayıcı bir şekilde sunar. Bu paket, veri keşfi aşamasında veri setinin genel özelliklerini anlamak için kullanılır.
skimr paketi, veri setinizdeki değişkenlerin türlerine göre istatistiksel özetler sunar. Örneğin, sayısal değişkenler için merkezi eğilim ölçüleri (ortalama, medyan), dağılım (standart sapma, min-max değerleri), faktör değişkenleri için sınıf sayısı, en sık rastlanan sınıf ve eksik veri durumları gibi bilgileri sunar.
Bu paket, veri setinin yapısını hızlıca anlamak ve önemli özelliklerini keşfetmek için kullanılır. Özellikle veri setlerinin keşfedilmesi, temizlenmesi ve analiz edilmesi aşamalarında oldukça faydalıdır. Bu, veri analiz sürecinde veriye daha derinlemesine bakmayı ve hangi analiz tekniklerinin kullanılacağına dair daha iyi bir anlayış geliştirmeyi sağlar.
Bunun yanında, modelsummary paketi de, R programlama dili için geliştirilmiş olan bir pakettir ve istatistiksel modellerin özetlenmesi, karşılaştırılması ve görselleştirilmesi için kullanılır. Bu paket, farklı türdeki modellerin çıktılarını standartlaştırarak, bunları karşılaştırmak ve analiz etmek için kullanıcıya kolaylık sağlar.
Bu paket genellikle doğrusal regresyon, lojistik regresyon, karar ağaçları, destek vektör makineleri gibi çeşitli istatistiksel ve makine öğrenimi modellerinin özet istatistiklerini, katsayılarını, belirlilik ölçülerini, hata ölçümlerini ve diğer önemli çıktıları sunar. Bunların yanı sıra, çıktıları tablolar halinde gösterir ve görselleştirmeler yaparak model performansını karşılaştırmak için grafikler oluşturabilir.
Bu paket, araştırmacılar, veri bilimcileri veya istatistikçilerin farklı modelleri anlamak, karşılaştırmak ve raporlamak için verimli bir araç sunar. Model sonuçlarını görselleştirme ve karşılaştırma açısından kullanışlıdır. Paket, model özetlerinin ötesinde, veri kümesine genel bakış, korelasyon matrisleri, (çok seviyeli) çapraz tablolar ve denge tabloları gibi son derece esnek veri özet tabloları üretmek için bir dizi araç da içerir.
# Paketin birkaç özelliğine bakalımlibrary(modelsummary)# kategorik verilere hızlı bir bakışdatasummary_skim(mpg, type ="categorical")
N
%
manufacturer
audi
18
7.7
chevrolet
19
8.1
dodge
37
15.8
ford
25
10.7
honda
9
3.8
hyundai
14
6.0
jeep
8
3.4
land rover
4
1.7
lincoln
3
1.3
mercury
4
1.7
nissan
13
5.6
pontiac
5
2.1
subaru
14
6.0
toyota
34
14.5
volkswagen
27
11.5
model
4runner 4wd
6
2.6
a4
7
3.0
a4 quattro
8
3.4
a6 quattro
3
1.3
altima
6
2.6
c1500 suburban 2wd
5
2.1
camry
7
3.0
camry solara
7
3.0
caravan 2wd
11
4.7
civic
9
3.8
corolla
5
2.1
corvette
5
2.1
dakota pickup 4wd
9
3.8
durango 4wd
7
3.0
expedition 2wd
3
1.3
explorer 4wd
6
2.6
f150 pickup 4wd
7
3.0
forester awd
6
2.6
grand cherokee 4wd
8
3.4
grand prix
5
2.1
gti
5
2.1
impreza awd
8
3.4
jetta
9
3.8
k1500 tahoe 4wd
4
1.7
land cruiser wagon 4wd
2
0.9
malibu
5
2.1
maxima
3
1.3
mountaineer 4wd
4
1.7
mustang
9
3.8
navigator 2wd
3
1.3
new beetle
6
2.6
passat
7
3.0
pathfinder 4wd
4
1.7
ram 1500 pickup 4wd
10
4.3
range rover
4
1.7
sonata
7
3.0
tiburon
7
3.0
toyota tacoma 4wd
7
3.0
trans
auto(av)
5
2.1
auto(l3)
2
0.9
auto(l4)
83
35.5
auto(l5)
39
16.7
auto(l6)
6
2.6
auto(s4)
3
1.3
auto(s5)
3
1.3
auto(s6)
16
6.8
manual(m5)
58
24.8
manual(m6)
19
8.1
drv
4
103
44.0
f
106
45.3
r
25
10.7
fl
c
1
0.4
d
5
2.1
e
8
3.4
p
52
22.2
r
168
71.8
class
2seater
5
2.1
compact
47
20.1
midsize
41
17.5
minivan
11
4.7
pickup
33
14.1
subcompact
35
15.0
suv
62
26.5
# nümerik verilere hızlı bir bakışdatasummary_skim(mpg, type ="numeric")