library(dplyr)
library(nycflights13)Veri Birleştirme
Veri analizi sürecinde, çoğu zaman birden fazla tabloyu ortak bir anahtar üzerinden birleştirmemiz gerekir.
Bu işlem, farklı kaynaklardaki bilgileri tek bir veri yapısında bütünleştirmemizi sağlar.
Örneğin, bir tabloda müşteri bilgileri, diğerinde sipariş bilgileri olabilir; analiz yapmak için bu tabloları birleştirmemiz gerekir.
R’da veri birleştirme işlemleri hem base R fonksiyonları (merge()) hem de dplyr paketindeki join fonksiyonları (left_join(), inner_join(), vb.) ile yapılabilir. Bu bölümde iki yaklaşımı da aynı veri seti üzerinden adım adım göstereceğiz.
Tip
Amaç:
Bu bölümün sonunda, birleştirme türlerini ve hangi durumda hangisinin kullanılacağını öğreneceksiniz. Ayrıca aynı işlemi hem dplyr hem de base R ile nasıl yapabileceğinizi göreceksiniz.
Kullanacağımız Veri Setleri
Bu bölümde nycflights13 paketindeki veri setlerini kullanacağız. Bu paket, 2013 yılı New York uçuş verilerini içerir ve ilişkisel yapıdadır. Yani birkaç tablo, ortak anahtarlar aracılığıyla birbirine bağlanabilir.
| Tablo | İçerik | Anahtar Değişken | Kayıt Sayısı | Sütun Sayısı |
|---|---|---|---|---|
flights |
Uçuş detayları | carrier, dest |
336776 | 19 |
airlines |
Havayolu adları | carrier |
16 | 2 |
airports |
Havaalanı bilgileri | faa |
1458 | 8 |
glimpse(flights)Rows: 336,776
Columns: 19
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, …
$ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, …
$ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1…
$ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849,…
$ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851,…
$ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -1…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "…
$ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 4…
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N394…
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA",…
$ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD",…
$ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 1…
$ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, …
$ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6…
$ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0…
$ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 0…glimpse(airlines)Rows: 16
Columns: 2
$ carrier <chr> "9E", "AA", "AS", "B6", "DL", "EV", "F9", "FL", "HA", "MQ", "O…
$ name <chr> "Endeavor Air Inc.", "American Airlines Inc.", "Alaska Airline…glimpse(airports)Rows: 1,458
Columns: 8
$ faa <chr> "04G", "06A", "06C", "06N", "09J", "0A9", "0G6", "0G7", "0P2", "…
$ name <chr> "Lansdowne Airport", "Moton Field Municipal Airport", "Schaumbur…
$ lat <dbl> 41.13047, 32.46057, 41.98934, 41.43191, 31.07447, 36.37122, 41.4…
$ lon <dbl> -80.61958, -85.68003, -88.10124, -74.39156, -81.42778, -82.17342…
$ alt <dbl> 1044, 264, 801, 523, 11, 1593, 730, 492, 1000, 108, 409, 875, 10…
$ tz <dbl> -5, -6, -6, -5, -5, -5, -5, -5, -5, -8, -5, -6, -5, -5, -5, -5, …
$ dst <chr> "A", "A", "A", "A", "A", "A", "A", "A", "U", "A", "A", "U", "A",…
$ tzone <chr> "America/New_York", "America/Chicago", "America/Chicago", "Ameri…Anahtar Değişken Nedir?
Birleştirme işlemlerinde kullanılan sütunlara anahtar değişken denir. Bu değişkenler, iki tablo arasında eşleştirmeyi sağlar. Örneğin:
flightstablosundakicarrier,airlinestablosundakicarrierile eşleştirilir.flightstablosundakidest,airportstablosundakifaaile eşleştirilir.
Note
Anahtar Değişken Özellikleri
İki tabloda da aynı bilgiyi temsil eder.
Veri tipleri uyumlu olmalıdır (örneğin, her ikisi de karakter olmalı).
Tekil veya tekrar eden değerler içerebilir. Tekrarlara göre ilişki türü (1–1, 1–N, N–M) belirlenir.
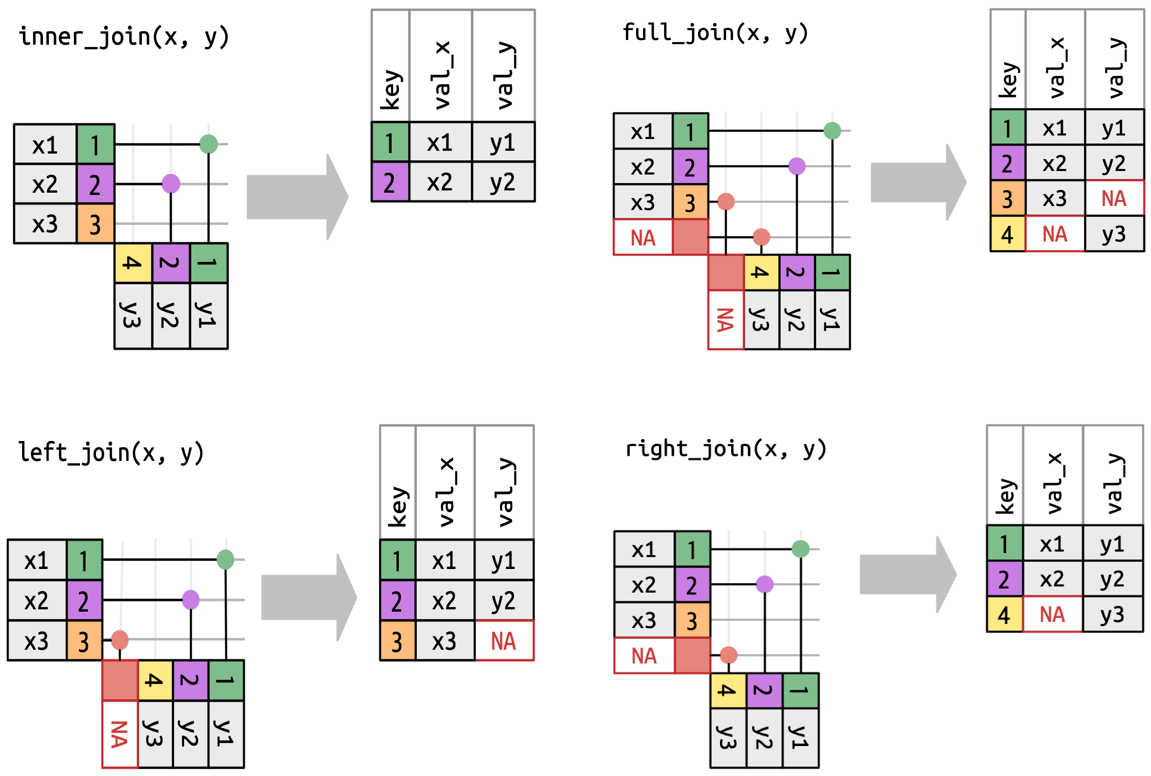
Join Kavramı ve Türleri
Join Nedir?
Join, iki veya daha fazla veri tablosunu ortak bir anahtar üzerinden birleştirme işlemidir. Sonuçta, tablolar tek bir veri çerçevesinde birleştirilir. Join türleri, hangi satırların korunacağına veya eleneceğine göre farklılık gösterir.
| Join Türü | Tanım | Tutulan Satırlar |
|---|---|---|
left_join |
Soldaki tüm satırları korur, sağdan eşleşenleri getirir | Tüm sol tablo |
inner_join |
Her iki tabloda eşleşen satırları getirir | Ortak anahtarlar |
right_join |
Sağdaki tüm satırları korur | Tüm sağ tablo |
full_join |
Her iki tablodaki tüm satırları birleştirir | Her iki tablo |
semi_join |
Sadece sol tablodan, eşleşen satırların alt kümesini getirir | Sol tablo (eşleşenler) |
anti_join |
Sol tablodan, eşleşmeyen satırları getirir | Sol tablo (eşleşmeyenler) |
Kardinalite (İlişki Türü)
İki tablo arasındaki ilişki, anahtar değişkenlerin yapısına bağlıdır:
| İlişki Türü | Tanım | Örnek |
|---|---|---|
| 1–1 (bire bir) | Her anahtar her tabloda bir kez geçer | T.C. kimlik numarası ↔︎ kişi |
| 1–N (bire çok) | Sol tablo tekil, sağ tablo tekrar içerir | Havayolu ↔︎ Uçuşlar |
| N–M (çoktan çok) | Her iki tabloda da tekrarlar vardır | Öğrenci ↔︎ Ders |
Bu durum, birleştirme sonrası satır sayısını doğrudan etkiler. Örneğin 1–N ilişkisinde satır sayısı artabilir.
R’de Join Yaklaşımları
R dilinde iki temel yaklaşım vardır:
| Yaklaşım | Fonksiyon | Paket |
|---|---|---|
| Base R | merge() |
Temel R |
| Tidyverse | left_join(), inner_join(), right_join(), full_join(), semi_join(), anti_join() |
dplyr |
Note
dplyr fonksiyonları daha okunabilir, tutarlı, ve pipe (%>%) yapısı ile çalışmaya uygundur.
Ancak merge() hâlâ birçok eski kodda ve küçük projelerde yaygın biçimde kullanılır.
Bu yüzden bu bölümde her iki yöntemi de göreceğiz.
Left Join
left_join() veya merge(..., all.x = TRUE) işlemleri, soldaki tablodaki tüm satırları koruyup, sağdaki tablodan yalnızca eşleşen kayıtları ekler. Bu en sık kullanılan birleştirme türüdür; çünkü genellikle “asıl veri setini” korumak isteriz.
Amaç: Her uçuşun carrier bilgisine karşılık gelen havayolu adını ekleyelim. Yani flights tablosundaki carrier değişkenini, airlines tablosundaki carrier ile eşleştireceğiz.
Beklenti
- Satır sayısı flights ile aynı kalmalı.
- Eşleşmeyen
carrierdeğerleri varsaNAgözükecek. - Sonuçta yeni sütun:
name(= havayolu adı).
fl_joined <- flights %>%
left_join(airlines, by = "carrier")
# Satır sayısı değişti mi?
tibble(
onceki = nrow(flights),
sonraki = nrow(fl_joined)
)# A tibble: 1 × 2
onceki sonraki
<int> <int>
1 336776 336776Sonuç değişmedi: left_join() soldaki tabloyu (flights) esas alır.
Yeni değişkenleri görelim:
fl_joined %>%
select(year, month, day, carrier, name) %>%
distinct(carrier, name) %>%
arrange(carrier) %>%
head(10)# A tibble: 10 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
Note
Burada name sütunu airlines tablosundan geldi.
Eğer iki tabloda aynı isimli başka sütunlar olsaydı, dplyr otomatik olarak .x ve .y sonekleri eklerdi.
Base R ile Aynı İşlem
Base R’de aynı işlem merge() ile yapılır. all.x = TRUE parametresi, soldan birleştirme anlamına gelir.
fl_joined_base <- merge(
flights,
airlines,
by = "carrier",
all.x = TRUE
)
# Satır sayısı kontrolü
c(before = nrow(flights), after = nrow(fl_joined_base))before after
336776 336776 head(fl_joined_base[c("carrier", "name")], 10) carrier name
1 9E Endeavor Air Inc.
2 9E Endeavor Air Inc.
3 9E Endeavor Air Inc.
4 9E Endeavor Air Inc.
5 9E Endeavor Air Inc.
6 9E Endeavor Air Inc.
7 9E Endeavor Air Inc.
8 9E Endeavor Air Inc.
9 9E Endeavor Air Inc.
10 9E Endeavor Air Inc.| Özellik | dplyr::left_join() |
base::merge() |
|---|---|---|
| Sözdizimi | Daha okunaklı (by = "carrier") |
Uzun, parametre odaklı |
| Varsayılan | Sadece belirttiğin by üzerinden |
Eğer by yoksa, ortak isimleri bulup otomatik join yapar (dikkat!) |
| Sonekler | .x ve .y |
.x ve .y veya .1 ve .2 |
| Performans | Genelde daha hızlı | Büyük veride yavaş olabilir |
| Okunabilirlik | 👍 | 🟡 |
Küçük Deneme: Eşleşmeyen Anahtar Durumu
Varsayalım airlines tablosundan bir satırı çıkaralım ve join yapalım; ne olur?
airlines_miss <- airlines %>% filter(carrier != "UA")
fl_test <- flights %>% left_join(airlines_miss, by = "carrier")
fl_test %>%
filter(is.na(name)) %>%
distinct(carrier) %>%
head()# A tibble: 1 × 1
carrier
<chr>
1 UA Sonuçta name = NA olan satırlar, airlines tablosunda karşılığı olmayan taşıyıcılardır.
Note
Bu tip satırlar veri tutarlılığı açısından önemlidir.
Gerçek analizlerde bu tür durumlar genellikle hatalı veya eksik kod anlamına gelir.
Kısa Özet
left_join(): soldaki tüm satırları korur.merge(..., all.x = TRUE): aynı işlevi base R’de yapar.Eşleşmeyen kayıtlar →
NA.Kontrol: satır sayısı değişmemeli.
Kod tabloları eklemek için en güvenli yöntemdir.
Inner Join
inner_join() veya merge(..., all = FALSE) işlemleri, iki tablodaki ortak anahtar değerlerine sahip satırları getirir. Yani her iki tabloda da eşleşen kayıtlar kalır; eşleşmeyenler atılır.
Amaç: Yalnızca hem flights hem de airlines tablolarında karşılığı olan havayolu kodlarını içeren satırları tutmak.
Beklenti
- Satır sayısı
flights’tan daha az olabilir. - Her iki tablodan da
carriereşleşmeyenler çıkarılır. NAdeğer olmamalıdır çünkü sadece eşleşenler alınır.
dplyr ile Inner Join
fl_inner <- flights %>%
inner_join(airlines, by = "carrier")
tibble(
flights_satir = nrow(flights),
inner_join_satir = nrow(fl_inner)
)# A tibble: 1 × 2
flights_satir inner_join_satir
<int> <int>
1 336776 336776Görüldüğü gibi satır sayısı azaldıysa, bazı carrier değerleri yalnızca bir tabloda var demektir. Sonuçtan küçük bir örnek:
fl_inner %>%
select(year, month, day, carrier, name) %>%
distinct(carrier, name) %>%
arrange(carrier) %>%
head(10)# A tibble: 10 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
Tip
inner_join() genellikle veri kesişimlerini bulmak için kullanılır. Örneğin, yalnızca hem satış listesinde hem stok listesinde bulunan ürünleri görmek istediğinizde.
Base R ile Inner Join
Aynı mantık merge() fonksiyonunda varsayılan olarak geçerlidir. Yani all = FALSE (veya hiç yazmazsanız) inner join anlamına gelir.
fl_inner_base <- merge(
flights,
airlines,
by = "carrier",
all = FALSE
)
c(before = nrow(flights), after = nrow(fl_inner_base))before after
336776 336776 head(fl_inner_base[c("carrier", "name")], 10) carrier name
1 9E Endeavor Air Inc.
2 9E Endeavor Air Inc.
3 9E Endeavor Air Inc.
4 9E Endeavor Air Inc.
5 9E Endeavor Air Inc.
6 9E Endeavor Air Inc.
7 9E Endeavor Air Inc.
8 9E Endeavor Air Inc.
9 9E Endeavor Air Inc.
10 9E Endeavor Air Inc.| Özellik | dplyr::inner_join() |
base::merge() |
|---|---|---|
| Varsayılan davranış | Yalnızca eşleşenleri tutar | Aynı |
| Satır sayısı | Azalabilir | Azalabilir |
NA değerler |
Oluşmaz | Oluşmaz |
| Kullanım alanı | Eşleşen kayıtları filtrelemek | Eşleşen kayıtları filtrelemek |
Note
Kısa Hatırlatma:
inner_join() sadece ortak anahtarları getirir. Bir tabloda olup diğerinde olmayan kayıtlar tamamen dışlanır. Bu nedenle veri kaybı olmaması istenen durumlarda left_join() tercih edilmelidir.
Right Join ve Full Join
Bu iki join türü, kapsayıcı birleştirmeler olarak adlandırılır.
Amaç, iki tablodaki tüm bilgileri korumaktır — ancak satırların hangi taraftan korunduğu değişir.
Right Join
right_join() veya merge(..., all.y = TRUE) işlemleri, sağdaki tablonun tüm satırlarını korur.
Soldaki tablodan yalnızca eşleşen kayıtlar getirilir.
Amaç: Tüm airlines kayıtlarını koruyalım, fakat flights tablosundan sadece eşleşenleri alalım. Bu, “sağ tarafı referans alan” bir birleştirmedir.
dplyr ile Right Join
fl_right <- flights %>%
right_join(airlines, by = "carrier")
tibble(
flights_satir = nrow(flights),
airlines_satir = nrow(airlines),
right_join_satir = nrow(fl_right)
)# A tibble: 1 × 3
flights_satir airlines_satir right_join_satir
<int> <int> <int>
1 336776 16 336776fl_right %>%
select(carrier, name) %>%
distinct(carrier, name)# A tibble: 16 × 2
carrier name
<chr> <chr>
1 UA United Air Lines Inc.
2 AA American Airlines Inc.
3 B6 JetBlue Airways
4 DL Delta Air Lines Inc.
5 EV ExpressJet Airlines Inc.
6 MQ Envoy Air
7 US US Airways Inc.
8 WN Southwest Airlines Co.
9 VX Virgin America
10 FL AirTran Airways Corporation
11 AS Alaska Airlines Inc.
12 9E Endeavor Air Inc.
13 F9 Frontier Airlines Inc.
14 HA Hawaiian Airlines Inc.
15 YV Mesa Airlines Inc.
16 OO SkyWest Airlines Inc.
Note
right_join() işlemi özellikle “kod tablosu” tarafındaki tüm değerlerin korunmasını istediğimiz durumlarda kullanılır.
Örneğin: tüm müşteri listesi sağda, yalnızca satış yapanlar soldaysa.
Base R ile Right Join
Base R’de aynı işlem merge(..., all.y = TRUE) parametresiyle yapılır.
fl_right_base <- merge(
flights,
airlines,
by = "carrier",
all.y = TRUE
)
c(before = nrow(airlines), after = nrow(fl_right_base))before after
16 336776 head(fl_right_base[c("carrier", "name")], 10) carrier name
1 9E Endeavor Air Inc.
2 9E Endeavor Air Inc.
3 9E Endeavor Air Inc.
4 9E Endeavor Air Inc.
5 9E Endeavor Air Inc.
6 9E Endeavor Air Inc.
7 9E Endeavor Air Inc.
8 9E Endeavor Air Inc.
9 9E Endeavor Air Inc.
10 9E Endeavor Air Inc.Full Join
full_join() veya merge(..., all = TRUE) işlemleri, her iki tablodaki tüm anahtar değerlerini birleştirir.
Eşleşmeyen satırların bulunduğu taraflarda NA değerler oluşur.
Amaç: flights ve airlines tablolarını tüm anahtarlarla birleştirelim. Böylece her iki tarafta olup diğerinde olmayan kayıtlar da görünür.
dplyr ile Full Join
fl_full <- flights %>%
full_join(airlines, by = "carrier")
tibble(
flights_satir = nrow(flights),
airlines_satir = nrow(airlines),
full_join_satir = nrow(fl_full)
)# A tibble: 1 × 3
flights_satir airlines_satir full_join_satir
<int> <int> <int>
1 336776 16 336776fl_full %>%
select(carrier, name) %>%
distinct(carrier, name) %>%
arrange(carrier) %>%
head(10)# A tibble: 10 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air Base R ile Full Join
Base R’de all = TRUE kullanıldığında full join elde edilir:
fl_full_base <- merge(
flights,
airlines,
by = "carrier",
all = TRUE
)
c(before = nrow(flights) + nrow(airlines), after = nrow(fl_full_base))before after
336792 336776 head(fl_full_base[c("carrier", "name")], 10) carrier name
1 9E Endeavor Air Inc.
2 9E Endeavor Air Inc.
3 9E Endeavor Air Inc.
4 9E Endeavor Air Inc.
5 9E Endeavor Air Inc.
6 9E Endeavor Air Inc.
7 9E Endeavor Air Inc.
8 9E Endeavor Air Inc.
9 9E Endeavor Air Inc.
10 9E Endeavor Air Inc.Özet
| Join Türü | dplyr Fonksiyonu | Base R Eşdeğeri | Korunan Taraf | Eşleşmeyenler |
|---|---|---|---|---|
| Left Join | left_join() |
merge(..., all.x = TRUE) |
Sol tablo | Sağ taraf NA |
| Right Join | right_join() |
merge(..., all.y = TRUE) |
Sağ tablo | Sol taraf NA |
| Full Join | full_join() |
merge(..., all = TRUE) |
Her iki tablo | Her iki tarafta da NA olabilir |
Note
full_join() verilerin iki farklı kaynaktan geldiği ve birleştirmenin tamlığı kontrol edilmek istendiği durumlarda kullanışlıdır. Örneğin: iki dönem verisini, iki kurum listesini veya iki sürümü birleştirirken.
Filtreleme Türü Join’ler (Semi Join ve Anti Join)
Bu iki join türü, tablo yapısını değiştirmez; yalnızca satır seçimi (filtreleme) yapar. Yani semi_join() ve anti_join() yeni sütunlar eklemez, sadece sol tablodan bazı satırları seçer. Bu işlemler SQL’de sırasıyla WHERE EXISTS ve WHERE NOT EXISTS karşılığına denktir.
semi_join()
semi_join() sol tablodaki satırlardan, sağ tablodaki anahtarlarla eşleşenleri tutar. Eşleşmeyen satırlar atılır. Yeni sütun eklenmez, sadece satır sayısı azalabilir.
Amaç: flights tablosundan, airlines tablosunda karşılığı bulunan carrier kayıtlarını alalım.
dplyr ile Semi Join
fl_semi <- flights %>%
semi_join(airlines, by = "carrier")
tibble(
flights_satir = nrow(flights),
semi_join_satir = nrow(fl_semi)
)# A tibble: 1 × 2
flights_satir semi_join_satir
<int> <int>
1 336776 336776fl_semi %>%
select(carrier) %>%
distinct(carrier) %>%
arrange(carrier)# A tibble: 16 × 1
carrier
<chr>
1 9E
2 AA
3 AS
4 B6
5 DL
6 EV
7 F9
8 FL
9 HA
10 MQ
11 OO
12 UA
13 US
14 VX
15 WN
16 YV
Note
semi_join() özellikle veri filtreleme veya “kesişimde olan kayıtları koruma” amacıyla kullanılır. Örneğin, sadece aktif müşteriler listesinde bulunan siparişleri görmek istediğinizde.
Base R ile Semi Join Benzeri İşlem
Base R’de doğrudan semi_join() yoktur, ancak aynı etkiyi merge() veya %in% operatörüyle elde edebiliriz.
fl_semi_base <- subset(
flights,
carrier %in% airlines$carrier
)
unique(fl_semi_base$carrier) [1] "UA" "AA" "B6" "DL" "EV" "MQ" "US" "WN" "VX" "FL" "AS" "9E" "F9" "HA" "YV"
[16] "OO"Yukarıdaki işlemde flights içinden sadece airlines’ta yer alan carrier değerlerine sahip satırlar alındı. Yani bu da semi_join() ile aynı sonucu verir.
💡 Neden
semi_join() Kullanılır?
Bazı durumlarda yalnızca bir tablodaki kayıtların, başka bir tabloda var olup olmadığını kontrol etmek isteriz.
Bu durumda inner_join() gereksiz ek sütunlar üretir, filter() ise özellikle birden fazla anahtar değişken olduğunda karmaşık hale gelir.
semi_join() bu iki uç arasında denge kurar ve yalnızca eşleşen satırları döndürür, ama sadece sol tablonun sütunlarını korur.
Böylece hem daha okunaklı hem de ilişkiselliği koruyan bir filtreleme yapılmış olur.
anti_join()
anti_join() ise tam tersini yapar: sol tablodaki satırlardan, sağda eşleşmeyenleri getirir. Bu, veri temizliği için çok kullanışlıdır.
Amaç: flights tablosunda olup airlines tablosunda karşılığı olmayan carrier değerlerini bulalım.
dplyr ile Anti Join
fl_anti <- flights %>%
anti_join(airlines, by = "carrier")
fl_anti %>%
select(carrier) %>%
distinct()# A tibble: 0 × 1
# ℹ 1 variable: carrier <chr>Bu, flights içinde olup airlines tablosunda bulunmayan carrier kodlarını listeler. Bu, veri kalitesi kontrolünde çok işe yarar. Örneğin, flights verisinde bir carrier kodu geçiyor ama bu kod airlines tablosunda tanımlı değilse, muhtemelen bu kod hatalı ya da eski bir değerdir.
Note
anti_join() veri bütünlüğü testleri için güçlü bir araçtır.
Örneğin; satış tablosundaki müşteri kodlarından bazıları müşteri kayıt tablosunda yoksa bu durum veri tutarsızlığına işaret eder.
Base R ile Anti Join Benzeri İşlem
Aynı mantığı base R’de %in% operatörüyle kurabiliriz:
fl_anti_base <- subset(
flights,
!(carrier %in% airlines$carrier)
)
unique(fl_anti_base$carrier)character(0)Özet
| Join Türü | Amaç | dplyr Fonksiyonu | Base R Yaklaşımı | Dönen Satırlar |
|---|---|---|---|---|
| Semi Join | Eşleşenleri getirir | semi_join() |
subset(..., %in%) |
Sol tablodan, eşleşenler |
| Anti Join | Eşleşmeyenleri getirir | anti_join() |
subset(..., !%in%) |
Sol tablodan, eşleşmeyenler |
Tip
Özetle:
Bu iki fonksiyon tabloyu “filtreler”, yeni sütun eklemez.
semi_join()→ ortak kayıtları bulur.anti_join()→ eksik veya hatalı kayıtları bulur. Özellikle veri temizliği, kalite kontrolü ve kod doğrulama süreçlerinde sıklıkla kullanılır.
Join İşlemlerinde Anahtar Yönetimi
🔑 Anahtar Değişkenlerin İsimleri Farklıysa
Bazı durumlarda iki tablodaki anahtar sütunların isimleri aynı olmayabilir. Örneğin flights tablosunda dest, airports tablosunda ise faa değişkeni aynı bilgiyi temsil eder. Bu durumda, her iki tabloda da hangi sütunun kullanılacağını by argümanı ile açıkça belirtmemiz gerekir.
✅ dplyr Örneği
flights %>%
left_join(airports, by = c("dest" = "faa")) %>%
select(dest, name, lat, lon) %>%
head()# A tibble: 6 × 4
dest name lat lon
<chr> <chr> <dbl> <dbl>
1 IAH George Bush Intercontinental 30.0 -95.3
2 IAH George Bush Intercontinental 30.0 -95.3
3 MIA Miami Intl 25.8 -80.3
4 BQN <NA> NA NA
5 ATL Hartsfield Jackson Atlanta Intl 33.6 -84.4
6 ORD Chicago Ohare Intl 42.0 -87.9Burada "dest" = "faa" ifadesi:
Sol tablodaki (
flights)destsütunu,Sağ tablodaki (
airports)faasütunu ile eşleştirileceğini belirtir.
✅ Base R Örneği
Base R’de aynı işlem şu şekilde yapılır:
merge(
flights,
airports,
by.x = "dest", # sol tablodaki değişken
by.y = "faa", # sağ tablodaki değişken
all.x = TRUE
)[c("dest", "name", "lat", "lon")] %>% head() dest name lat lon
1 ABQ Albuquerque International Sunport 35.04022 -106.6092
2 ABQ Albuquerque International Sunport 35.04022 -106.6092
3 ABQ Albuquerque International Sunport 35.04022 -106.6092
4 ABQ Albuquerque International Sunport 35.04022 -106.6092
5 ABQ Albuquerque International Sunport 35.04022 -106.6092
6 ABQ Albuquerque International Sunport 35.04022 -106.6092Eğer iki tabloda anahtar isimleri aynıysa, by = "carrier" veya by.x = "carrier", by.y = "carrier" şeklinde açıkça belirtmek her zaman iyi bir pratiktir. Böylece hem okunabilirlik artar hem de gelecekte değişiklik olduğunda hatalar önlenir.
🧩 Birden Fazla Anahtar Değişken ile Join
Bazen iki tabloyu birden fazla değişken üzerinden eşleştirmemiz gerekir. Örneğin flights tablosunu başka bir tabloyla hem yıl, hem ay, hem de havayolu kodu (carrier) üzerinden birleştirmek isteyebiliriz. Bu durumda anahtarları by argümanı içinde bir vektör olarak belirtiriz.
✅ dplyr Örneği
# Örnek amaçlı küçük bir tablo oluşturalım
stats <- flights %>%
group_by(year, month, carrier) %>%
summarise(avg_delay = mean(dep_delay, na.rm = TRUE), .groups = "drop")
# Aynı üç değişken üzerinden birleştirme
fl_enriched <- flights %>%
left_join(stats, by = c("year", "month", "carrier"))
fl_enriched %>% select(year, month, carrier, avg_delay) %>% head()# A tibble: 6 × 4
year month carrier avg_delay
<int> <int> <chr> <dbl>
1 2013 1 UA 8.33
2 2013 1 UA 8.33
3 2013 1 AA 6.93
4 2013 1 B6 9.49
5 2013 1 DL 3.85
6 2013 1 UA 8.33✅ Base R Örneği
fl_enriched_base <- merge(
flights,
stats,
by = c("year", "month", "carrier"),
all.x = TRUE
)
head(fl_enriched_base[c("year", "month", "carrier", "avg_delay")]) year month carrier avg_delay
1 2013 1 9E 16.88251
2 2013 1 9E 16.88251
3 2013 1 9E 16.88251
4 2013 1 9E 16.88251
5 2013 1 9E 16.88251
6 2013 1 9E 16.88251Birden fazla değişken kullanmak özellikle panel veriler veya zaman serileri ile çalışırken oldukça yaygındır. Ancak anahtarların her iki tabloda da aynı sırayla ve aynı tipte (örneğin karakter veya sayı) olduğuna emin olun. )
🔄 Farklı İsimli Birden Fazla Anahtar Değişken ile Join
Eğer iki tabloda birden fazla anahtar değişken var ve bu değişkenlerin isimleri her iki tabloda aynı değilse,
her bir çifti eşleştirerek açıkça belirtmemiz gerekir.
✅ dplyr Örneği
# flights -> other_tbl_keys : sadece anahtarlar, tekilleştirilmiş
other_tbl_keys <- flights %>%
distinct(year, month, day, carrier) %>%
rename(yil = year, ay = month, gun = day)
fl_merge <- flights %>%
left_join(
other_tbl_keys,
by = c("year" = "yil", "month" = "ay", "day" = "gun", "carrier" = "carrier")
)
# Satır sayısı beklenen: flights kadar
dplyr::tibble(before = nrow(flights), after = nrow(fl_merge))# A tibble: 1 × 2
before after
<int> <int>
1 336776 336776✅ Base R Örneği
other_tbl_keys <- flights %>%
distinct(year, month, day, carrier) %>%
rename(yil = year, ay = month, gun = day)
fl_merge_ok2 <- merge(
flights, other_tbl_keys,
by.x = c("year","month","day","carrier"),
by.y = c("yil","ay","gun","carrier"),
all.x = TRUE,
sort = FALSE
)
c(before = nrow(flights), after = nrow(fl_merge_ok2))before after
336776 336776
💡 Neden
distinct() ile tekilleştirdik? (dplyr + Base R)
flights’tan türettiğimiz sağ tablolarda (other_tbl_keys) anahtarlar (year, month, day, carrier) tekrar ediyordu.
Bu durumda left_join() / merge() her eşleşen kombinasyonu çarpan şekilde birleştirir.
→ N–M patlaması: satır sayısı çok büyür, bellek/işlem süresi artar.
Çözüm: Sağ tabloyu join öncesinde distinct() ile tekilleştir → ilişkiyi N–M’den 1–N’e indir.
Böylece her anahtar yalnızca bir kez eşleşir; hem hızlı hem mantıksal olarak doğru sonuç alırsın.